Ispirer Website
Ispirer Toolkit Overview
Free Trial
How to Optimize Migration of Schema and Data
To optimize the migration process, we recommend splitting the conversion into multiple threads using the following approach:
- (Instance 1) In the first instance of the tool, select all the tables (and other objects (views, functions, etc.) if any) that you want to convert.
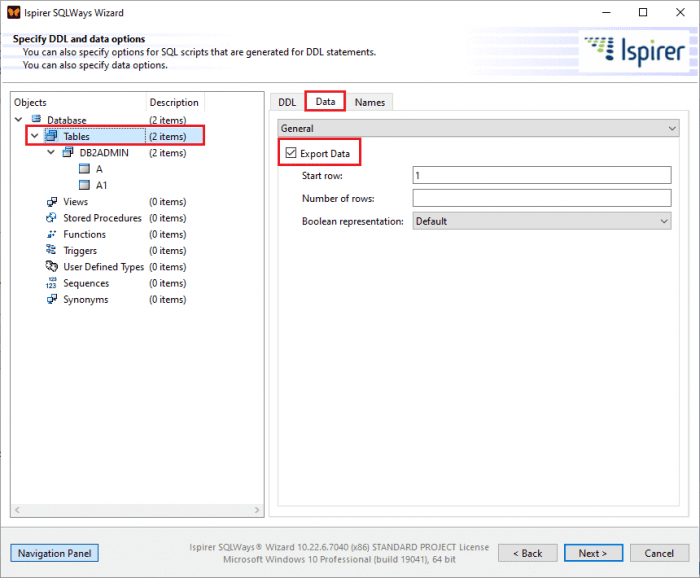
On the “Conversion Options“ page, click “Tables” in the object tree, and on the “Data” tab uncheck the “Export Data” option:

This will allow our tool to convert all DDL, indexes and constraints without wasting time on data export. Next, on the “DDL” tab, in the “Table Options” dropdown list select, “Fast” for the “Import option for tables” option:

This option allows us to download constraints and indexes separately from the DDL, so that we can then import them separately into the database.
- (Instance 2 - N) In the rest of the instances only data will be converted.
On the “DDL” tab, in the “Generation Options” dropdown list, you need to uncheck the “Generate DDL” option. Thus, only data will be uploaded and converted in these threads:

The “Export Data” option should now be enabled.
If necessary, the scope may be divided into approximately equal parts of data to speed up the conversion process.
There are two ways to split data in a table:
a) If you select some tables to convert, you can specify the starting row and number of rows to upload into the “Tables” section on the “Data” tab. For example, you can upload N rows starting from the first into one instance, the remaining rows into the second, starting from N + 1 rows, and so on. There can be any number of such instances:

b) You can specify an SQL condition for each table. If your table has a key, you can write an SQL condition using the source database SQL language that will partition the table (more detailed instruction can be found here).
For each instance, we also need to select “Fast” for the “Import option for tables” option. Next, the algorithm is as follows – first, start the conversion of all streams (make sure that the “Start Import Automatically” checkbox is unchecked for all threads):

Once all the tables have been converted in the first instance (Instance 1), you need to upload ONLY the DDLs of those tables into the target database. To do this, in the “Import Options” window, leave only the “DDL” item checked (if other objects are selected for migration, you may also check the appropriate items, e.g. “Views”, “Triggers” etc.):

Next, you need to wait for the data export in each thread to complete and then import the data into the target database (Instance 2 - N). Please note that in this case, only the “Data” item should be checked in the “Import Options” window.

Once all the data is loaded into the database, you need to select only “Indexes” and “Constraints” in the main instance (Instance 1) in the “Import Options” window and perform the import:

Such a mechanism allows to convert all tables and data in multiple instances, without fear that any problems may arise due to keys and dependencies between objects.
If you have any other questions, please contact us at support@ispirer.com