About Ispirer Systems
Ispirer Home Page Database Migration Application Conversion Downloads
Usage examples of the sqlways.ini options
[Usage example]:DISABLE_CONSTRAINTS
Source code (Teradata)
The purpose of this article is to demonstrate how the DISABLE_CONSTRAINTS option involves on conversion results.
Here below you may see the sample of the source code of the table with Primary key and Foreign Key constraints in the block 1, the converted code without the option in the block 2 and the converted code with option set.
CREATE TABLE MyTable1 ( Column1 varchar(10) NOT NULL, Column2 integer, Column3 varchar(32), Column4 int, FOREIGN KEY (Column2, Column3) REFERENCES MyTable2 (Column2, Column3) ) UNIQUE PRIMARY INDEX pk01 (Column1) ;
smth text
Converted Vertica Analytic Database code
(without option DISABLE_CONSTRAINTS or with option DISABLE_CONSTRAINTS=No/Empty value)
CREATE TABLE MyTable1 ( Column1 VARCHAR(10) NOT NULL, Column2 INT, Column3 VARCHAR(32), Column4 VARCHAR(10), CONSTRAINT fk_MyTable1 FOREIGN KEY(Column2,Column3) REFERENCES MyTable2(Column2,Column3) ENABLED, constraint pk01 PRIMARY KEY(Column1) ENABLED );
Converted Vertica Analytic Databaser code (with option DISABLE_CONSTRAINTS=Yes)
CREATE TABLE MyTable1 ( Column1 VARCHAR(10) NOT NULL, Column2 INT, Column3 VARCHAR(32), Column4 VARCHAR(10), CONSTRAINT fk_MyTable1 FOREIGN KEY(Column2,Column3) REFERENCES MyTable2(Column2,Column3) DISABLED, constraint pk01 PRIMARY KEY(Column1) DISABLED );
As you can see when the DISABLE_CONSTRAINTS option is not set, the ENABLED keyword is added by default. The same will happen if the option is set to “No” or the value is not specified. If the option is set to “Yes”, then the DISABLED keyword will be added to the constraints.
[Usage example]:CONVERT_SP_WITH_OUTPUT_PARAMS
The purpose of this article is to demonstrate how the option CONVERT_SP_WITH_OUTPUT_PARAMS involves on conversion results.
Here below you may see the sample of the source code of the procedure in the block 1, the converted code without the option in the 2nd block and the converted code with option set.
It should also be taken into account that the option PROCEDURE_WITH_OUTPUT_PARAMS=No in both cases.
Source code (Informix)
CREATE PROCEDURE out_proc()
RETURNING
INTEGER AS col1, INTEGER AS col2, integer as col3;
DEFINE v01 INTEGER;
DEFINE v03 INTEGER;
let v01 = 0;
let v03 = 0;
insert into tab1 values(v01, v03,v03);
SELECT sum(y1), max(y2) INTO v01, v03 FROM tab1;
RETURN v01,0,v03;
END PROCEDURE;
Converted MS SQL Server code (by default)
CREATE PROCEDURE dbo.out_proc AS
BEGIN
declare @v01 INT
declare @v03 INT
DECLARE @SWF_FLAG1 INT
IF OBJECT_ID(N'tempdb..#swtmp_out_proc') IS NULL
begin
CREATE TABLE #swtmp_out_proc
(
col1 INT null,
col2 INT null,
col3 INT null,
swc_identity INT identity
)
set @SWF_FLAG1 = 1
end
SET @v01 = 0
SET @v03 = 0
insert into dbo.tab1 values(@v01, @v03,@v03)
SELECT @v01 = sum(y1), @v03 = max(y2) FROM dbo.tab1
if @@ROWCOUNT = 0
select @v01 = null, @v03 = null
insert into #swtmp_out_proc
select @v01 as col1,0 as col2,@v03 as col3
if @SWF_FLAG1 = 1
SELECT col1,col2,col3
from #swtmp_out_proc order by swc_identity
RETURN
END
Converted MS SQL Server code (with option CONVERT_SP_WITH_OUTPUT_PARAMS=S:\\out\\swf_stored_procedures.txt)
CREATE PROCEDURE dbo.out_proc @SWP_Ret_Value INT = NULL OUTPUT ,@SWP_Ret_Value1 INT = NULL OUTPUT ,@SWP_Ret_Value2 INT = NULL OUTPUT , @SWV_Output_Set BIT = 1
AS
BEGIN
declare @v01 INT
declare @v03 INT
SET @v01 = 0
SET @v03 = 0
insert into dbo.tab1 values(@v01, @v03,@v03)
SELECT @v01 = sum(y1), @v03 = max(y2) FROM dbo.tab1
if @@ROWCOUNT = 0
select @v01 = null, @v03 = null
set @SWP_Ret_Value = @v01
set @SWP_Ret_Value1 = 0
set @SWP_Ret_Value2 = @v03
if @SWV_Output_Set = 1
select @v01 as col1,0 as col2,@v03 as col3
RETURN
END
The content of the swf_stored_procedures.txt:
<Procedures>
<Procedure Name="out_proc"/>
</Procedures>
[Usage example]:PROCEDURE_WITH_OUTPUT_PARAMS
The purpose of this note is to demonstrate how the option PROCEDURE_WITH_OUTPUT_PARAMS changes conversion results.
Here below there are the sample of the source code in the block 1, the converted code with the option set to “Yes” in the block 2 and the converted code with option set to “No”.
Source code (Informix)
CREATE PROCEDURE colors_list() RETURNING VARCHAR(30), CHAR(6) RETURN 'Red', 'FF0000'; END PROCEDURE;
Converted MS SQL Server code (by default)
CREATE PROCEDURE dbo.colors_list @SWP_Ret_Value VARCHAR(30) = NULL OUTPUT ,@SWP_Ret_Value1 CHAR(6) = NULL OUTPUT
AS
BEGIN
set @SWP_Ret_Value = 'Red'
set @SWP_Ret_Value1 = 'FF0000'
RETURN
END
Converted MS SQL Server code (with option PROCEDURE_WITH_OUTPUT_PARAMS=No)
CREATE PROCEDURE dbo.colors_list AS
BEGIN
DECLARE @SWF_FLAG1 INT
IF OBJECT_ID(N'tempdb..#swtmp_colors_list') IS NULL
begin
CREATE TABLE #swtmp_colors_list
(
unnamed_col_1 VARCHAR(30) null,
unnamed_col_2 CHAR(6) null,
swc_identity INT identity
)
set @SWF_FLAG1 = 1
end
insert into #swtmp_colors_list
select 'Red','FF0000'
if @SWF_FLAG1 = 1
SELECT unnamed_col_1,unnamed_col_2
from #swtmp_colors_list order by swc_identity
RETURN
END
[Usage example]: CONVERT_SP_RETSTATUS_OUTPARAM
The result values may be return from function with RETURN statement or from procedure with OUTPUT parameter, as displayed below:
Source code (Oracle)
create function ret_one
RETURN NUMBER
as
begin
return 1 ;
end;
Converted code (MSSQL Server) (CONVERT_SP_RETSTATUS_OUTPARAM=No, by default)
CREATE function RET_ONE()
RETURNS FLOAT
AS
begin
return 1
end
Converted code (MSSQL Server) (CONVERT_SP_RETSTATUS_OUTPARAM=Yes)
CREATE PROCEDURE RET_ONE @SWP_RET_VALUE FLOAT = NULL OUTPUT
AS
begin
set @SWP_RET_VALUE = 1
RETURN
end
The option may be set in GUI:
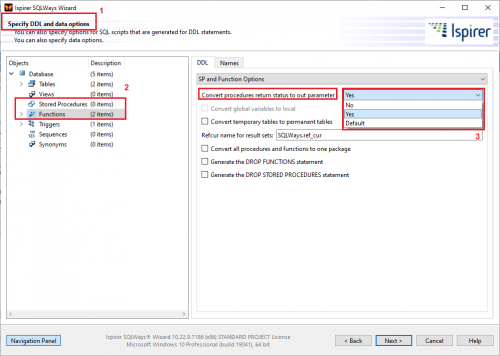
[Usage example]: RETURN_RESULT_FROM_SP_AND_FN
The result sets in PosgreSQL may be returned in the following ways: by using the table, the SETOF type and using the refcursor. The samples of the output with different options set displayed below:
Source code (MSSQL Server)
create table test_data(c1 int, c2 varchar(22)) create procedure result_set_pr @p1 Date as select @p1 as c0, c1, c2 from test_data
Converted PostgreSQL code (RETURN_RESULT_FROM_SP_AND_FN=TABLE, by default)
CREATE OR REPLACE FUNCTION result_set_pr(v_p1 DATE)
RETURNS table
(
c0 DATE,
c1 INTEGER,
c2 VARCHAR(22)
) LANGUAGE plpgsql
AS $$
BEGIN
return query select v_p1 as c0, c1, c2 from test_data;
END; $$;
Converted PostgreSQL code (RETURN_RESULT_FROM_SP_AND_FN=SETOF)
CREATE TYPE result_set_pr_rs AS(c0 DATE, c1 INTEGER, c2 VARCHAR(22));
CREATE OR REPLACE FUNCTION result_set_pr(v_p1 DATE)
RETURNS SETOF result_set_pr_rs LANGUAGE plpgsql
AS $$
BEGIN
return query select v_p1 as c0, c1, c2 from test_data;
END; $$;
Converted PostgreSQL code (RETURN_RESULT_FROM_SP_AND_FN=REFCURSOR)
CREATE OR REPLACE PROCEDURE result_set_pr(v_p1 DATE, INOUT SWV_RefCur refcursor)
LANGUAGE plpgsql
AS $$
BEGIN
open SWV_RefCur for
select v_p1 as c0, c1, c2 from test_data;
END; $$;
[Usage example]: IDENTITY_TO_SERIAL
PostgreSQL allows to use 2 ways of automatic integer numbers generation: by using the IDENTITY property or using the SERIAL pseudo-data type. The result of using the option with values No and Yes displayed in the table below. The data type of the source IDENTITY column will be converted into appropriate SERIAL column: SMALLINT will become SMALLSERIAL, INTEGER goes into SERIAL, and BIGINT into BIGSERIAL accordingly.
Source code (DB2 LUW)
CREATE TABLE TABIDENTCOLUMN ( ID INTEGER GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1) NOT NULL, NAME CHAR(5) );
CREATE TABLE TABIDENTCOLUMN_2 ( ID SMALLINT GENERATED ALWAYS AS IDENTITY (START WITH 3, INCREMENT BY 1) NOT NULL, NAME CHAR(5) )
Converted PostgreSQL code (IDENTITY_TO_SERIAL=No)
CREATE TABLE TABIDENTCOLUMN
(
ID INTEGER GENERATED ALWAYS AS IDENTITY(START 1 INCREMENT 1) NOT NULL,
NAME CHAR(5)
);
CREATE TABLE TABIDENTCOLUMN_2
(
ID SMALLINT GENERATED ALWAYS AS IDENTITY(START 3 INCREMENT 1) NOT NULL,
NAME CHAR(5)
);
Converted PostgreSQL code (IDENTITY_TO_SERIAL=Yes)
CREATE TABLE TABIDENTCOLUMN
(
ID SERIAL,
NAME CHAR(5)
);
CREATE TABLE TABIDENTCOLUMN_2
(
ID SMALLSERIAL,
NAME CHAR(5)
);
ALTER SEQUENCE TABIDENTCOLUMN_2_ID_seq RESTART WITH 3 INCREMENT BY 1;
[Usage example]: TABLE_TYPE_CONVERSION
PostgreSQL does not support table types, and there are 2 ways to simulate Oracle logic.
By default, table types (TYPE IS TABLE, VARRAYS) are converted using Arrays. Another way is to convert table types into arrays in PostgreSQL(using temporary tables) as it displayed in column 2 of the table.
Source code (Oracle)
CREATE TYPE employee AS OBJECT (
id NUMBER,
Name VARCHAR(300)
);
CREATE TYPE employees_tab IS TABLE OF employee;
CREATE OR REPLACE PROCEDURE hire(EMPLOYEES in out employees_tab,
id NUMBER, Name VARCHAR) AS
NEW_EMPLOYEES employees_tab := employees_tab();
BEGIN
EMPLOYEES.Extend(1);
EMPLOYEES(EMPLOYEES.count) := employee(id, Name);
FOR i IN EMPLOYEES.first..EMPLOYEES.last
LOOP
INSERT INTO emp_tab values (EMPLOYEES(i).id, EMPLOYEES(i).Name);
END LOOP;
INSERT INTO EMP_TAB SELECT * FROM TABLE(EMPLOYEES);
NEW_EMPLOYEES.Extend(EMPLOYEES.count);
NEW_EMPLOYEES.Delete;
END;
Converted PostgreSQL code (TABLE_TYPE_CONVERSION=Tables)
CREATE TYPE EMPLOYEE AS(id DOUBLE PRECISION,Name VARCHAR(300));
-- CREATE TYPE EMPLOYEES_TAB IS TABLE OF employee;
CREATE OR REPLACE PROCEDURE HIRE(id DOUBLE PRECISION,Name VARCHAR(4000))
LANGUAGE plpgsql
AS $$
BEGIN
create temporary table if not exists SWT_HIRE_NEW_EMPLOYEES
(
SWC_INDEX INTEGER NOT NULL,
ID DOUBLE PRECISION,
NAME VARCHAR(300)
);
DELETE FROM SWT_HIRE_NEW_EMPLOYEES;
FOR i IN COALESCE((SELECT MAX(SWT_HIRE_EMPLOYEES.SWC_INDEX) FROM SWT_HIRE_EMPLOYEES)+1,1) .. COALESCE((SELECT MAX(SWT_HIRE_EMPLOYEES.SWC_INDEX) FROM SWT_HIRE_EMPLOYEES),
0)+1
LOOP
INSERT INTO SWT_HIRE_EMPLOYEES(SWC_Index) VALUES(i);
END LOOP;
IF NOT EXISTS(SELECT 1 FROM SWT_HIRE_EMPLOYEES WHERE SWT_HIRE_EMPLOYEES.SWC_INDEX =(SELECT COUNT(*) FROM SWT_HIRE_EMPLOYEES)) then
INSERT INTO SWT_HIRE_EMPLOYEES VALUES((SELECT COUNT(*) FROM SWT_HIRE_EMPLOYEES),NULL);
END IF;
UPDATE SWT_HIRE_EMPLOYEES SET id = id,Name = Name
WHERE SWT_HIRE_EMPLOYEES.SWC_INDEX =(SELECT COUNT(*) FROM SWT_HIRE_EMPLOYEES);
FOR i IN(SELECT MIN(SWC_INDEX) FROM SWT_HIRE_EMPLOYEES) ..(SELECT MAX(SWC_INDEX) FROM SWT_HIRE_EMPLOYEES)
LOOP
INSERT INTO EMP_TAB values((SELECT SWT_HIRE_EMPLOYEES.ID FROM SWT_HIRE_EMPLOYEES WHERE SWC_INDEX = i), (SELECT
SWT_HIRE_EMPLOYEES.NAME FROM SWT_HIRE_EMPLOYEES WHERE SWC_INDEX = i));
END LOOP;
INSERT INTO EMP_TAB SELECT * FROM EMPLOYEES;
FOR i IN COALESCE((SELECT MAX(SWT_HIRE_NEW_EMPLOYEES.SWC_INDEX) FROM SWT_HIRE_NEW_EMPLOYEES)+1,1) .. COALESCE((SELECT
MAX(SWT_HIRE_NEW_EMPLOYEES.SWC_INDEX) FROM SWT_HIRE_NEW_EMPLOYEES),0)+(SELECT COUNT(*) FROM SWT_HIRE_EMPLOYEES)
LOOP
INSERT INTO SWT_HIRE_NEW_EMPLOYEES(SWC_Index) VALUES(i);
END LOOP;
DELETE FROM SWT_HIRE_NEW_EMPLOYEES;
END; $$;
Converted PostgreSQL code (TABLE_TYPE_CONVERSION=Arrays, by default)
CREATE TYPE EMPLOYEE AS(id DOUBLE PRECISION,Name VARCHAR(300));
-- CREATE TYPE EMPLOYEES_TAB IS TABLE OF employee;
CREATE OR REPLACE PROCEDURE HIRE(INOUT EMPLOYEES EMPLOYEE[] ,
ID DOUBLE PRECISION, NAME VARCHAR(4000))
LANGUAGE plpgsql
AS $$
DECLARE
EMPLOYEES_REC EMPLOYEE;
NEW_EMPLOYEES EMPLOYEE[] default array[]::EMPLOYEE[] ;
BEGIN
EMPLOYEES[swf_array_length(EMPLOYEES)+1] := null;
EMPLOYEES[swf_array_length(EMPLOYEES)] := row(ID,NAME);
FOR i IN array_lower(EMPLOYEES,1) .. array_upper(EMPLOYEES,1)
LOOP
EMPLOYEES_REC := EMPLOYEES[i];
INSERT INTO EMP_TAB values(EMPLOYEES_REC.ID, EMPLOYEES_REC.NAME);
EMPLOYEES[i] := EMPLOYEES_REC;
END LOOP;
INSERT INTO EMP_TAB SELECT * FROM unnest(EMPLOYEES);
for i in 1 .. swf_array_length(EMPLOYEES) loop
NEW_EMPLOYEES[swf_array_length(NEW_EMPLOYEES)+1] := null;
end loop;
NEW_EMPLOYEES := array[]:: EMPLOYEE[];
END; $$;
[Usage example]:CONVERT_ROUTINE_TO_SP_RESULTSET
By default, the routine that returns the resultset will be converted into procedure with additional out parameters (column 2). In case of option value CONVERT_ROUTINE_TO_SP_RESULTSET=Yes, the result will be returned by the SELECT statement.
Source code (Informix)
CREATE PROCEDURE sp_call_sp_with_param2(p1 char(10), p2 integer)
RETURNING INTEGER,CHAR,INTEGER;
DEFINE v1 INTEGER;
DEFINE v2 CHAR(2);
DEFINE v3 INTEGER;
select col1, col2, col3 INTO v1,v2,v3 from tab1;
RETURN v1,v2,v3;
END PROCEDURE;
Converted code (MSSQL) (CONVERT_ROUTINE_TO_SP_RESULTSET=No, by default)
CREATE PROCEDURE dbo.sp_call_sp_with_param2 @p1 CHAR(10), @p2 INT,@SWP_Ret_Value INT = NULL OUTPUT ,@SWP_Ret_Value1 CHAR = NULL OUTPUT ,@SWP_Ret_Value2 INT = NULL OUTPUT
AS
BEGIN
declare @j_qte INT
declare @v1 INT
declare @v2 CHAR(2)
declare @v3 INT
select @v1 = col1, @v2 = col2, @v3 = col3 from dbo.tab1
if @@ROWCOUNT = 0
select @v1 = null, @v2 = null, @v3 = null
set @SWP_Ret_Value = @v1
set @SWP_Ret_Value1 = @v2
set @SWP_Ret_Value2 = @v3
RETURN
END
Converted code (MSSQL) (CONVERT_ROUTINE_TO_SP_RESULTSET=Yes)
CREATE PROCEDURE dbo.sp_call_sp_with_param2 @p1 CHAR(10), @p2 INT
AS
BEGIN
declare @v1 INT
declare @v2 CHAR(2)
declare @v3 INT
select @v1 = col1, @v2 = col2, @v3 = col3 from dbo.tab1
if @@ROWCOUNT = 0
select @v1 = null, @v2 = null, @v3 = null
select @v1, @v2, @v3
RETURN
END
[Usage example]: ORACLE_GET_CHAR_COLUMN_SIZE
Usage example for different values:
Source code (Oracle)
create table nihon.tabchar(col1 char(1 char), col2 char(2 char), col3 char(6), col4 char(12), col5 numeric)
Converted code (PostgreSQL)(ORACLE_GET_CHAR_COLUMN_SIZE=CHAR/Empty, by default)
CREATE TABLE NIHON.TABCHAR
(
COL1 CHAR(2),
COL2 CHAR(4),
COL3 CHAR(6),
COL4 CHAR(12),
COL5 DECIMAL(38,0)
);
Converted code (PostgreSQL)(ORACLE_GET_CHAR_COLUMN_SIZE=BYTE)
CREATE TABLE NIHON.TABCHAR
(
COL1 CHAR(1),
COL2 CHAR(2),
COL3 CHAR(6),
COL4 CHAR(12),
COL5 DECIMAL(38,0)
);
[Usage example]: FULLY_QUALIFY_IDENTIFIERS
There are 3 views, 3 functions and 3 procedures in this example. Different pieces of each object kind include one of 3 tables: tab9 from default schema and tab9, tab10 from “db” schema.
EMPTY_SCHEMA = OUTSCHEMA = schemaname2
If FULLY_QUALIFY_IDENTIFIERS=Yes, then each object has schemaname2 near its name (because schemaname2 was specified in the OUTSCHEMA).
If FULLY_QUALIFY_IDENTIFIERS=No, then parent objects (in this case it's views, functions, procedures) have schemaname2 near its name (because schemaname2 was specified in the OUTSCHEMA). But child objects (in this case tables) have same schema names as in the source code.
Usage example for different values:
Source code (Oracle)
create or replace view viewfqi1 as select * from tab9 create or replace view viewfqi2 as select * from db.tab9 create or replace view viewfqi3 as select * from db.tab10
| Converted code (PostgreSQL) (FULLY_QUALIFY_IDENTIFIERS=Yes, by default) | Converted code (PostgreSQL) (FULLY_QUALIFY_IDENTIFIERS=No) |
|---|---|
| CREATE OR REPLACE VIEW schemaname2.VIEWFQI1(COL1,COL2,COL3,COL4,COL5,COL6) AS select COL1,COL2,COL3,COL4,COL5,COL6 from schemaname2.TAB92; CREATE OR REPLACE VIEW schemaname2.VIEWFQI2(COL1,COL2,COL3,COL4,COL5,COL6) AS select COL1,COL2,COL3,COL4,COL5,COL6 from schemaname2.TAB9; CREATE OR REPLACE VIEW schemaname2.VIEWFQI3(COL1,COL2,COL3,COL4,COL5,COL6) AS select COL1,COL2,COL3,COL4,COL5,COL6 from schemaname2.TAB10; | CREATE OR REPLACE VIEW schemaname2.VIEWFQI1(COL1,COL2,COL3,COL4,COL5,COL6) AS select COL1,COL2,COL3,COL4,COL5,COL6 from tab9; CREATE OR REPLACE VIEW schemaname2.VIEWFQI2(COL1,COL2,COL3,COL4,COL5,COL6) AS select COL1,COL2,COL3,COL4,COL5,COL6 from db.tab9; CREATE OR REPLACE VIEW schemaname2.VIEWFQI3(COL1,COL2,COL3,COL4,COL5,COL6) AS select COL1,COL2,COL3,COL4,COL5,COL6 from db.tab10; |
Source code (Oracle)
create or replace FUNCTION funcfqi1 (p1 in number)
RETURN number
IS
x number;
BEGIN
select col1 into x from tab9;
return 1;
end;
create or replace FUNCTION funcfqi2 (p1 in number)
RETURN number
IS
x number;
BEGIN
select col1 into x from db.tab9;
return 1;
end;
create or replace FUNCTION funcfqi3 (p1 in number)
RETURN number
IS
x number;
BEGIN
select col1 into x from db.tab10;
return 1;
end;
Converted code (PostgreSQL) (FULLY_QUALIFY_IDENTIFIERS=Yes, by default)
CREATE OR REPLACE FUNCTION schemaname2.FUNCFQI1(in P1 DOUBLE PRECISION)
RETURNS DOUBLE PRECISION LANGUAGE plpgsql
AS $$
DECLARE
X DOUBLE PRECISION;
BEGIN
select COL1 into STRICT X from schemaname2.TAB92;
return 1;
END; $$;
CREATE OR REPLACE FUNCTION schemaname2.FUNCFQI2(in P1 DOUBLE PRECISION)
RETURNS DOUBLE PRECISION LANGUAGE plpgsql
AS $$
DECLARE
X DOUBLE PRECISION;
BEGIN
select COL1 into STRICT X from schemaname2.TAB9;
return 1;
END; $$;
CREATE OR REPLACE FUNCTION schemaname2.FUNCFQI3(in P1 DOUBLE PRECISION)
RETURNS DOUBLE PRECISION LANGUAGE plpgsql
AS $$
DECLARE
X DOUBLE PRECISION;
BEGIN
select COL1 into STRICT X from schemaname2.TAB10;
return 1;
END; $$;
Converted code (PostgreSQL) (FULLY_QUALIFY_IDENTIFIERS=No)
CREATE OR REPLACE FUNCTION schemaname2.FUNCFQI1(in P1 DOUBLE PRECISION)
RETURNS DOUBLE PRECISION LANGUAGE plpgsql
AS $$
DECLARE
X DOUBLE PRECISION;
BEGIN
select COL1 into STRICT X from tab9;
return 1;
END; $$;
CREATE OR REPLACE FUNCTION schemaname2.FUNCFQI2(in P1 DOUBLE PRECISION)
RETURNS DOUBLE PRECISION LANGUAGE plpgsql
AS $$
DECLARE
X DOUBLE PRECISION;
BEGIN
select COL1 into STRICT X from db.tab9;
return 1;
END; $$;
CREATE OR REPLACE FUNCTION schemaname2.FUNCFQI3(in P1 DOUBLE PRECISION)
RETURNS DOUBLE PRECISION LANGUAGE plpgsql
AS $$
DECLARE
X DOUBLE PRECISION;
BEGIN
select COL1 into STRICT X from db.tab10;
return 1;
END; $$;
Source code (Oracle)
create or replace procedure procfqi1(p1 IN number) is begin insert into tab9(col1, col2, col3, col4) values (p1, p1, p1, p1); end; create or replace procedure procfqi2(p1 IN number) is begin insert into db.tab9(col1, col2, col3, col4) values (p1, p1, p1, p1); end; create or replace procedure procfqi3(p1 IN number) is begin insert into db.tab10(col1, col2, col3, col4) values (p1, p1, p1, p1); end;
Converted code (PostgreSQL) (FULLY_QUALIFY_IDENTIFIERS=Yes, by default)
CREATE OR REPLACE FUNCTION schemaname2.PROCFQI1(IN P1 DOUBLE PRECISION) RETURNS VOID LANGUAGE plpgsql AS $$ BEGIN insert into schemaname2.TAB92(COL1, COL2, COL3, COL4) values(P1, P1, P1, P1); RETURN; END; $$; CREATE OR REPLACE FUNCTION schemaname2.PROCFQI2(IN P1 DOUBLE PRECISION) RETURNS VOID LANGUAGE plpgsql AS $$ BEGIN insert into schemaname2.TAB9(COL1, COL2, COL3, COL4) values(P1, P1, P1, P1); RETURN; END; $$; CREATE OR REPLACE FUNCTION schemaname2.PROCFQI3(IN P1 DOUBLE PRECISION) RETURNS VOID LANGUAGE plpgsql AS $$ BEGIN insert into schemaname2.TAB10(COL1, COL2, COL3, COL4) values(P1, P1, P1, P1); RETURN; END; $$;
Converted code (PostgreSQL) (FULLY_QUALIFY_IDENTIFIERS=No)
CREATE OR REPLACE FUNCTION schemaname2.PROCFQI1(IN P1 DOUBLE PRECISION) RETURNS VOID LANGUAGE plpgsql AS $$ BEGIN insert into tab9(COL1, COL2, COL3, COL4) values(P1, P1, P1, P1); RETURN; END; $$; CREATE OR REPLACE FUNCTION schemaname2.PROCFQI2(IN P1 DOUBLE PRECISION) RETURNS VOID LANGUAGE plpgsql AS $$ BEGIN insert into db.tab9(COL1, COL2, COL3, COL4) values(P1, P1, P1, P1); RETURN; END; $$; CREATE OR REPLACE FUNCTION schemaname2.PROCFQI3(IN P1 DOUBLE PRECISION) RETURNS VOID LANGUAGE plpgsql AS $$ BEGIN insert into db.tab10(COL1, COL2, COL3, COL4) values(P1, P1, P1, P1); RETURN; END; $$;
[Usage example]: IDENTITY_COLUMN_TYPE
In PostgreSQL it is allowed to specify different clauses for IDENTITY column. In order to use the required one, IDENTITY_COLUMN_TYPE option may be set.
Here below it is demonstrated how the option IDENTITY_COLUMN_TYPE impact the conversion result: there are the sample of the source code in the column 1, the converted code with the option set to “Always” (or with an empty option) in column 2 and the converted code with option set to “Default” in the last column.
Source code (Microsoft SQL Server)
CREATE TABLE ident_table_pg ( c1 INT IDENTITY, c2 VARCHAR(22) );
Converted PostgreSQL code (with option IDENTITY_COLUMN_TYPE=ALWAYS, by default)
CREATE TABLE ident_table_pg ( c1 INTEGER GENERATED ALWAYS AS IDENTITY(START 1 INCREMENT 1) NOT NULL, c2 VARCHAR(22) );
Converted PostgreSQL code (with option IDENTITY_COLUMN_TYPE=DEFAULT)
CREATE TABLE ident_table_pg ( c1 INTEGER GENERATED BY DEFAULT AS IDENTITY(START 1 INCREMENT 1) NOT NULL, c2 VARCHAR(22) );
[Usage example]: TRIGGER_RECURSION_LVL
In order to avoid trigger execution that will fire the same or other triggers endless times, in other words the trigger recursion, the appropriate WHEN statement may be add to check the trigger nesting level.
The following example shows the triggers conversion results depend on option TRIGGER_RECURSION_LVL values: there are the sample of the trigger source code in the column 1, the converted trigger function and trigger code when the option value is not set in column 2 and the converted code with option set to TRIGGER_RECURSION_LVL=0 in column 3. The trigger in column 2 will cause infinite its execution that finally ends up with the error “ERROR: stack depth limit exceeded”. To resolve it, the check need to be add by the option -it may be done by specifying the option like it is demonstrated in column 3.
Source code (Microsoft SQL Server)
CREATE TRIGGER trigOnTab1
ON tab1
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON
update tab1
set c2 = UPPER(i.c2)
from tab1 t
inner join inserted i on i.c1 = t.c1
END
Converted PostgreSQL code (with option TRIGGER_RECURSION_LVL= , by default)
CREATE OR REPLACE FUNCTION trigOnTab1_TrFunc() RETURNS TRIGGER LANGUAGE plpgsql AS $$ BEGIN BEGIN update tab1 t set c2 = UPPER(i.c2) from new_table i WHERE i.c1 = t.c1; END; RETURN NULL; END; $$; DROP TRIGGER IF EXISTS trigOnTab1 ON tab1; CREATE TRIGGER trigOnTab1 AFTER UPDATE ON tab1 REFERENCING NEW TABLE AS new_table FOR STATEMENT EXECUTE PROCEDURE trigOnTab1_TrFunc();
Converted PostgreSQL code (with option TRIGGER_RECURSION_LVL=0)
CREATE OR REPLACE FUNCTION trigOnTab1_TrFunc() RETURNS TRIGGER LANGUAGE plpgsql AS $$ BEGIN BEGIN update tab1 t set c2 = UPPER(i.c2) from new_table i WHERE i.c1 = t.c1; END; RETURN NULL; END; $$; DROP TRIGGER IF EXISTS trigOnTab1 ON tab1; CREATE TRIGGER trigOnTab1 AFTER UPDATE ON tab1 REFERENCING NEW TABLE AS new_table FOR STATEMENT WHEN (pg_trigger_depth() <1) EXECUTE PROCEDURE trigOnTab1_TrFunc();
[Usage example]: RETURN_TABLE_SQL_MACRO for [ORACLE]
By default, IspirerToolkit converts table-returning functions to pipelined ones. But starting with Oracle 21c we can use SQL_MACRO functionality.
Source code PostgreSQL
create function get_film(p_title character varying)
returns table(film_title character varying, film_release_year integer)
language plpgsql as $$
begin
return query
select title, year
from film_table
where title = p_title;
end; $$
Converted Oracle code by default
create or replace type dt_get_film as object(film_title varchar2(32767),film_release_year number(10,0));
create or replace type get_film_set as table of dt_get_film;
create or replace function get_film(p_title in varchar2)
return
get_film_set pipelined
as
begin
for retrow in(select title as swa_al1, year as swa_al2
from film_table
where title = p_title)
loop
pipe row(dt_get_film(retrow.swa_al1,retrow.swa_al2));
end loop;
end;
Converted Oracle code version 21+ and option RETURN_TABLE_SQL_MACRO=Yes
create or replace function get_film(p_title in varchar2)
return varchar2 sql_macro(table)
as
begin
return q'{
select
retrow.swa_al1 as film_title,
retrow.swa_al2 as film_release_year
from(select title as swa_al1, year as swa_al2
from film_table
where title = p_title)retrow
}';
end;
[Usage example]: RETURN_STATUS_TO
The example below shows the difference in the way the resulting procedure is returned in both cases.
Source code ASE
create procedure sp_tab_ret_stat as declare @c_ch integer begin select @c_ch=col2 from tab_ret_stat where col1=4 IF ( @c_ch > 20 ) BEGIN SELECT 1 RETURN( -1 ) END RETURN( 0 ) end
Converted MySQL code by default (option RETURN_STATUS_TO=INOUT)
DELIMITER //
DROP PROCEDURE IF EXISTS sp_tab_ret_stat;
//
create procedure sp_tab_ret_stat(INOUT SWP_Ret_Value INT)
SWL_return:
BEGIN
DECLARE v_c_ch INT;
select col2 INTO v_c_ch from tab_ret_stat where col1 = 4;
IF (v_c_ch > 20) then
SELECT 1;
SET SWP_Ret_Value =(-1);
LEAVE SWL_return;
end if;
SET SWP_Ret_Value =(0);
LEAVE SWL_return;
END;
//
DELIMITER ;
Converted MySQL code and option RETURN_STATUS_TO=LOCAL
DELIMITER //
DROP PROCEDURE IF EXISTS sp_tab_ret_stat;
//
create procedure sp_tab_ret_stat()
SWL_return:
BEGIN
DECLARE v_c_ch INT;
DECLARE SWP_Ret_Value INT;
select col2 INTO v_c_ch from tab_ret_stat where col1 = 4;
IF (v_c_ch > 20) then
SELECT 1;
SET SWP_Ret_Value =(-1);
LEAVE SWL_return;
end if;
SET SWP_Ret_Value =(0);
LEAVE SWL_return;
END;
//
DELIMITER ;
[Usage example]:IMPORT_CLIENT_OPTIONS
The purpose of this article is to demonstrate how the IMPORT_CLIENT_OPTIONS option involves on conversion results. Here below you may see the sample of the command line of the table: Converted with empty value (IMPORT_CLIENT_OPTIONS=)
:create_table echo Creating table using the MySQL command line utility "C:\Program Files\MySQL\MySQL Workbench 8.0 CE\mysql.exe" --host=localhost --user=root --password=root --comments --port=3306 --force -vvv test1 < test_add_opt_tab.sql >> test_add_opt.log goto:eof
Converted with no empty value (IMPORT_CLIENT_OPTIONS=–init-command=“SET SESSION FOREIGN_KEY_CHECKS=0;”)
:create_table echo Creating table using the MySQL command line utility "C:\Program Files\MySQL\MySQL Workbench 8.0 CE\mysql.exe" host=localhost --user=root --password=root --comments --port=3306 – -init-command="SET SESSION FOREIGN_KEY_CHECKS=0;" -force -vvv test1 < test_add_opt_tab.sql >> test_add_opt.log goto:eof
[Usage example]:CONVERT_DBLINK_TO_SCHEMA
Source code Sybase ASE:
create view dbo.convert_dblink_to_schema as select ccdesk..test_tab1.col1, ccdesk..test_tab1.col2, model..tab2.col3, model..tab2.col4 from ccdesk..test_tab1, model..tab2 where ccdesk..test_tab1.col2 = model..tab2.col3
Converted Sybase ASE code by default:
create or replace view convert_dblink_to_schema as select test_tab1.col1 as col1, test_tab1.col2 as col2, tab2.col3 as col3, tab2.col4 as col4 from test_tab1, tab2 where test_tab1.col2 = tab2.col3;
Converted Sybase ASE code + option CONVERT_DBLINK_TO_SCHEMA=Yes:
create or replace view convert_dblink_to_schema as select test_tab1.col1 as col1, test_tab1.col2 as col2, tab2.col3 as col3, tab2.col4 as col4 from ccdesk.test_tab1, model.tab2 where test_tab1.col2 = tab2.col3;
[Usage example]:CONVERT_EXCEPT
By default, IspirerToolkit converts all calls of procedures, functions to calls of Java methods. But the objects that are specified in CONVERT_EXCEPT option will be called directly from the database.
The example below shows the difference in conversion of calls of object by default and when they are specified in option.
Source code Oracle
CREATE OR REPLACE PACKAGE BODY convertExceptOptionWithRegexp
AS
PROCEDURE CRUDPROC1
IS
v1 number;
BEGIN
PKG_CRMNP_CRUD.CL_BAT;
v1 := SP_CNR_GLPAM;
END;
END;
Converted Java code by default
public class Convertexceptoptionwithregexp {
private PkgCrmnpCrud pkgCrmnpCrud;
private SpCnrGlpam spCnrGlpam;
public Convertexceptoptionwithregexp() throws Exception,SQLException {
pkgCrmnpCrud = new PkgCrmnpCrud();
spCnrGlpam = new SpCnrGlpam();
}
public void crudproc1() throws Exception {
BigDecimal v1 = null;
pkgCrmnpCrud.clBat();
v1 = spCnrGlpam.spSpCnrGlpam();
}
}
Converted Java code with option CONVERT_EXCEPT=(?i)([\w]+_CRUD\b), SP_CNR_GLPAM
public class Convertexceptoptionwithregexp {
private static final org.slf4j.Logger LOGGER = org.slf4j.LoggerFactory.getLogger(Convertexceptoptionwithregexp.class);
public void crudproc1() throws SQLException, Exception {
Connection mConn = JDBCDataSource.getConnection();
BigDecimal v1 = null;
try(CallableStatement mStmt = mConn.prepareCall("{call PKG_CRMNP_CRUD.CL_BAT()}");) {
mStmt.execute();
SQLCursorHandler.getInstance().setFound();
}
catch (SQLException se) {
SQLCursorHandler.getInstance().handleExeption(se);
throw se;
}
try(CallableStatement mStmt = mConn.prepareCall("{? = call SP_CNR_GLPAM()}");) {
mStmt.registerOutParameter(1, Types.DECIMAL);
mStmt.execute();
v1 = mStmt.getBigDecimal(1);
SQLCursorHandler.getInstance().setFound();
}
catch(SQLException se) {
SQLCursorHandler.getInstance().handleExeption(se);
throw se;
}
if (!mConn.getAutoCommit()) {
mConn.commit();
}
}
}
[Usage example]:BL_ONLY
Source code (Informix 4GL)
function window_style() define xfontsize char(50) display xfontsize end function;
Converted Informix 4GL code (BL_ONLY=No)
static public void window_style()
{
string xfontsize = string.Empty;
GUIHelpers.DisplayString(xfontsize);
}
Converted Informix 4GL code (BL_ONLY=Yes)
public void window_style()
{
string xfontsize = string.Empty;
Stubs.display(xfontsize);
}
[Usage example]:CONCAT_NULL_STRINGS_AS_NULL
By default, Ispirer Toolkit converts string concatenation as is. But in order to reproduce the same behavior in the case of null strings in Oracle and PostgreSQL, we can add a check for the presence of nulls among the concatinating strings. And if there are null values, the resulting string becomes null.
The example below shows the difference in the way the resulting string is obtained in both cases. Source code PostgreSQL
create or replace procedure sp_concat_nulls() LANGUAGE plpgsql AS $$ DECLARE v_ret varchar(20) = null; v_str_null varchar(20); v_str1 varchar(20) = '1'; BEGIN v_ret := v_str_null || '' || v_str1; raise notice 'v_ret = %', v_ret; END; $$ -- output v_ret = <NULL>
Converted Oracle code by default
create or replace procedure sp_concat_nulls as
v_ret varchar2(20) := null;
v_str_null varchar2(20);
v_str1 varchar2(20) := '1';
BEGIN
v_ret := v_str_null || '' || v_str1;
DBMS_OUTPUT.PUT_LINE('v_ret = ' || v_ret);
END;
-- output
v_ret = 1
Converted Oracle code + option CONCAT_NULL_STRINGS_AS_NULL=Yes
create or replace procedure sp_concat_nulls as
v_ret varchar2(20) := null;
v_str_null varchar2(20);
v_str1 varchar2(20) := '1';
BEGIN
v_ret := case when greatest(v_str_null,v_str1) is null then null else v_str_null || '' || v_str1 end;
DBMS_OUTPUT.PUT_LINE('v_ret = ' || v_ret);
END;
-- output
v_ret = <NULL>
[Usage example]:TEMPDB_TABLES_TO_TEMPORARY_TABLES
Source code Sybase ASE
create procedure tempdb_tables_to_temporary_tables as create table tempdb..test_tab1(col1 int, col2 int) insert into tempdb..test_tab1 values(1,2) drop table tempdb..test_tab1
Converted code to PostgreSQL by default
create or replace procedure tempdb_tables_to_temporary_tables()
LANGUAGE plpgsql
AS $$
BEGIN
drop table IF EXISTS test_tab1 CASCADE;
create table test_tab1
(
col1 INTEGER,
col2 INTEGER
);
insert into test_tab1 values(1,2); drop table IF EXISTS test_tab1 CASCADE;
END; $$;
Converted code to PostgreSQL + option TEMPDB_TABLES_TO_TEMPORARY_TABLES=Yes
create or replace procedure tempdb_tables_to_temporary_tables()
LANGUAGE plpgsql
AS $$
BEGIN
drop table IF EXISTS test_tab1 CASCADE;
create TEMPORARY table test_tab1
(
col1 INTEGER,
col2 INTEGER
);
insert into test_tab1 values(1,2); drop table IF EXISTS test_tab1 CASCADE;
END; $$;
[Usage example]:DESIGN_PATTERN
Source code (Informix 4GL)
function test() call gethcall() end function;
Converted Informix 4GL code (DESIGN_PATTERN=Empty)
static public void test()
{
Isp.gethcall();
}
Converted Informix 4GL code (DESIGN_PATTERN=Swagger)
[HttpGet("test")]
[SwaggerOperation("Inst")]
public void test()
{
Isp.gethcall();
}
[Usage example]:DESIGN_PATTERN1
Source code (PBScripts)
$PBExportHeader$w_test.srw $PBExportComments$ forward global type w_test from window end type end forward global type w_test from window integer x = 1083 integer y = 336 integer width = 1577 integer height = 896 end type global w_test w_test
Converted PBScripts code (DESIGN_PATTERN=Empty)
public partial class w_test : WindowBase
{
#region Singleton
private static w_test _instance;
public static w_test Instance
{
get
{
if (_instance == null || ! _instance.IsLoaded)
{
_instance = new w_test();
}
return _instance;
}
}
#endregion
#region Constructors
public w_test()
{
InitializeComponent();
_instance = this;
}
#endregion
}
Converted PBScripts code (DESIGN_PATTERN=MVVM)
[HttpGet("test")]
[SwaggerOperation("Inst")]
public partial class w_test_srwViewModel : WindowBaseViewModel
{
#region Singleton
private static w_test_srwViewModel _instance;
public static w_test_srwViewModel Instance
{
get
{
if (_instance == null || _instance.IsClosed)
{
_instance = new w_test_srwViewModel();
}
return _instance;
}
}
#endregion
#region Constructors
public w_test_srwViewModel() : this(null)
{
}
public w_test_srwViewModel(UIElementViewModel parent) : base(parent)
{
_instance = this;
_instance.Parent = parent;
Name = "w_test";
Height = 896;
Width = 1577;
Margin = new ThicknessViewModel(1083, 336, 0, 0);
}
#endregion
#region ViewModel
#endregion
#region Classes
#endregion
}
[Usage example]:TABLES_DDL
To use the information about the structure of tables for a more correct migration, you can save the tables ddl to a file and then use it as if it were a migration with a connection. The example below shows the difference in the result when the table structure is taken into account and when it is not.
Let's say we have such a table and a query in Oracle. Table:
create table table1 (id int, str varchar(20), dt DATE); insert into table1 values (2, '10', current_date);
Query:
select case when id=str then 0 else 1 end, dt+1 from table1;
If we convert this query to PostgreSQL without having information about the structure of the table, it will remain the same. But when we run the query, we will get errors: 1) ERROR: operator does not exist: integer = character varying 2) ERROR: operator does not exist: timestamp without time zone + integer
To avoid such errors, we have to consider all types of columns. After adding the path to the file with the table ddl, we will get the following result:
Query:
select case when id = cast(NULLIF(str,'') as INTEGER) then 0 else 1 end, (dt+INTERVAL '1 day'):: date from table1;
As you can see, in this case, no errors will be issued, and the result of select will be correct. Source code Oracle
select
case when id=str
then 0 else 1 end,
dt+1
from table1;
Converted PostgreSQL code by default
select
case when id=str
then 0 else 1 end,
dt+1
from table1;
Converted PostgreSQL code + path to tables ddl
select
case when id = cast(NULLIF(str,'') as INTEGER)
then 0 else 1 end,
(dt+INTERVAL '1 day'):: date
from table1;
If this option does not work as expected, please contact our technical team: [email protected]
[Usage example]:AUTONOMOUS_TRANS
By default, Ispirer Toolkit adds PRAGMA AUTONOMOUS_TRANSACTION if the function contains DML operations.
The example below shows the difference in the resulting finction in both cases. Please compare: PostgreSQL source code
CREATE OR REPLACE FUNCTION fn_1() RETURNS text LANGUAGE plpgsql AS $$ DECLARE ret_val text; BEGIN ret_val := 'Ok'; insert into tab2 (a) VALUES (10); RETURN ret_val; END;$$;
Oracle AUTONOMOUS_TRANS=No
CREATE OR REPLACE FUNCTION fn_1 RETURN VARCHAR2 as ret_val varchar2(4000); BEGIN ret_val := 'Ok'; insert into tab2(a) VALUES(10); RETURN ret_val; END;
Oracle AUTONOMOUS_TRANS=Yes
CREATE OR REPLACE FUNCTION fn_1 RETURN VARCHAR2 as PRAGMA AUTONOMOUS_TRANSACTION; ret_val varchar2(4000); BEGIN ret_val := 'Ok'; insert into tab2(a) VALUES(10); commit; RETURN ret_val; END;
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: AUTONOMOUS_TRANSACTION_TO_DBLINK
The example below shows the difference in the resulting procedure in both cases. Please compare:
| Oracle source code | PostgreSQL AUTONOMOUS_TRANSACTION_TO_DBLINK=No | PostgreSQL AUTONOMOUS_TRANSACTION_TO_DBLINK=Yes |
|---|---|---|
CREATE PROCEDURE AUTO_TEST (id_value number, text_value varchar2) IS PRAGMA AUTONOMOUS_TRANSACTION; BEGIN INSERT INTO DSSUSER.AUTONOMOUS_EVENT (id, value) VALUES(id_value, text_value); COMMIT; END AUTO_TEST; | CREATE OR REPLACE PROCEDURE AUTO_TEST(id_value DOUBLE PRECISION, text_value VARCHAR) LANGUAGE plpgsql AS $$ BEGIN INSERT INTO AUTONOMOUS_EVENT(ID, VALUE) VALUES(id_value, text_value); COMMIT; END; $$; | CREATE OR REPLACE PROCEDURE AUTO_TEST(id_value DOUBLE PRECISION, text_value VARCHAR, IN is_recursive boolean DEFAULT false)
LANGUAGE plpgsql
AS $$
DECLARE
v_sql text;
BEGIN
IF is_recursive = FALSE THEN
begin
IF NOT EXISTS (SELECT 1 FROM dblink_get_connections()
WHERE dblink_get_connections@>'{myconn}') THEN
PERFORM dblink_connect('myconn', 'SWL_j2p9ecom_link');
END IF;
v_sql := format('CALL dssuser.AUTO_TEST( id_value => %L, text_value => %L, is_recursive => TRUE)', id_value, text_value);
PERFORM dblink_exec( 'myconn', v_sql);
end;
ELSE
--procedure body
insert into dssuser.autonomous_event values (id_value, text_value);
commit;
END IF;
END; $$;
|
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: MISSEDLOGIC
| Pascal source code | Converted Pascal code by default | Converted Pascal code with the MISSEDLOGIC=Yes option |
|---|---|---|
unit test1; interface implementation procedure test(); var par3 : integer; begin par3 := sum_proc2(); end; end. | public partial class test1Unit
{
public static void test()
{
int par3 = 0;
par3 = sum_proc2();
}
}
| public partial class test1Unit
{
public static void test()
{
int par3 = 0;
par3 = ((int) MissedLogic.sum_proc2());
}
}
+ new generated file in GeneratedCode\MissedLogic.cs:
namespace Missed
{
public class MissedLogic
{
public static object sum_proc2()
{
return null;
}
}
}
|
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: LOGGER
Please note: the option works only for the Oracle, SQL Server, Sybase ASE and Sybase ASA sources!
By default, Ispirer Toolkit uses the slf4j logging framework, but if the option is specified to log4j, the tool will use the log4j library.
The example below shows the difference between the default conversion and the conversion using the LOGGER=log4j option.
| Oracle source code | Converted to Java code by default | Converted to Java code with the LOGGER=log4j option |
|---|---|---|
CREATE PROCEDURE LOGGER_OPTION_EXAMPLE AS BEGIN INSERT INTO TAB_A VALUES (1, 'TEXT1'); END; | import java.sql.*;
import com.data.db.SQLCursorHandler;
import com.data.db.JDBCDataSource;
public class LoggerOptionExample {
private static final org.slf4j.Logger LOGGER = org.slf4j.LoggerFactory.getLogger(LoggerOptionExample.class);
public void spLoggerOptionExample() throws Exception {
Connection mConn = JDBCDataSource.getConnection();
try {
try(PreparedStatement mStmt = mConn.prepareStatement("INSERT INTO TAB_A VALUES (1, 'TEXT1')");) {
SQLCursorHandler.getInstance().setRowcount(mStmt.executeUpdate());
}
catch (SQLException se) {
SQLCursorHandler.getInstance().handleExeption(se);
throw se;
}
if (!mConn.getAutoCommit()) {
mConn.commit();
}
}
catch (Exception e) {
LOGGER.error(String.valueOf(e));
throw e;
}
finally {
if (mConn != null) {
mConn.close();
}
}
}
}
| import java.sql.*;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import com.data.db.SQLCursorHandler;
import com.data.db.JDBCDataSource;
public class LoggerOptionExample {
private static final Logger LOGGER = LogManager.getLogger(LoggerOptionExample.class);
public void spLoggerOptionExample() throws Exception {
Connection mConn = JDBCDataSource.getConnection();
try {
try(PreparedStatement mStmt = mConn.prepareStatement("INSERT INTO TAB_A VALUES (1, 'TEXT1')");) {
SQLCursorHandler.getInstance().setRowcount(mStmt.executeUpdate());
}
catch (SQLException se) {
SQLCursorHandler.getInstance().handleExeption(se);
throw se;
}
if (!mConn.getAutoCommit()) {
mConn.commit();
}
}
catch (Exception e) {
LOGGER.error(String.valueOf(e));
throw e;
}
finally {
if (mConn != null) {
mConn.close();
}
}
}
}
|
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: DEPENDENCY_INJECTION
Please note: the option works only for the Oracle to Java, SQL Server to Java directions!
By default, Ispirer Toolkit creates object dependencies in the traditional way, but if you specify the Spring option, the tool will use the Spring DI container for dependency injection.
The example below shows the difference in object creation dependencies by default and using the Spring dependency injection option.
| Oracle source code | Converted to Java code by default | Converted to Java code with the DEPENDENCY_INJECTION=Spring option |
|---|---|---|
CREATE PACKAGE BODY PKG_WITH_DEPENDENCY
IS
PROCEDURE SP
IS
BEGIN
SP_TO_INJECT;
PKG_TO_INJECT.SP_TO_INJECT;
END;
END;
| public class PkgWithDependency {
private static final org.slf4j.Logger LOGGER = org.slf4j.LoggerFactory.getLogger(PkgWithDependency.class);
private SpToInject spToInject;
private PkgToInject pkgToInject;
public PkgWithDependency() throws Exception,SQLException {
spToInject = new SpToInject();
pkgToInject = new PkgToInject();
}
public void sp() throws GeneralException {
try {
spToInject.spSpToInject();
pkgToInject.spToInject();
}
catch(Exception e) {
throw new GeneralException(e, LOGGER);
}
}
}
| @Service
@RequestScope
public class PkgWithDependency implements IPkgWithDependency {
private static final org.slf4j.Logger LOGGER = org.slf4j.LoggerFactory.getLogger(PkgWithDependency.class);
@Autowired
private ISpToInject spToInject;
@Autowired
private IPkgToInject pkgToInject;
@Override
public void sp() throws GeneralException {
try {
spToInject.spSpToInject();
pkgToInject.spToInject();
}
catch(Exception e) {
throw new GeneralException(e, LOGGER);
}
}
}
|
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: EXTRACT_SQL
Please note: the option works only for the Oracle to Java direction!
By default, Ispirer Toolkit specifies query lines directly in the code. With the EXTRACT_SQL=yes option, the tool extracts queries into XML files, one XML file per object, and retrieves the required query line from the XML file when it needs to be executed.
The example below shows the difference between the default conversion and the conversion using the EXTRACT_SQL=yes option.
| Oracle source code | Converted to Java code by default | Converted to Java code with the EXTRACT_SQL=yes option |
|---|---|---|
create procedure extract_sql_sample(id number) as v1 number; v2 varchar2(50); begin insert into tab1 values (1, 'text1'); select col1, col2 into v1, v2 from tab1 where col1 = id; end; | @Service
@Transactional
public class ExtractSqlSample implements IExtractSqlSample {
@Autowired
private JdbcTemplate jdbcTemplate;
private static final org.slf4j.Logger LOGGER = org.slf4j.LoggerFactory.getLogger(ExtractSqlSample.class);
private Integer errorCode = 0;
private String sqlState = "";
@Override
public void spExtractSqlSample(BigDecimal id)
throws GeneralException {
try {
Map<String, Object> resMap;
BigDecimal v1 = null;
String v2 = null;
jdbcTemplate.update("insert into tab1 values (1, 'text1')");
resMap = jdbcTemplate.queryForMap("select col1, col2 from tab1 where col1 = ?", id);
v1 = QueryUtility.toObject(resMap.get("col1"), BigDecimal.class );
v2 = QueryUtility.toObject(resMap.get("col2"), String.class );
}
catch (Exception e) {
throw new GeneralException(e, LOGGER);
}
}
}
| @Service
@Transactional
public class ExtractSqlSample implements IExtractSqlSample {
@Autowired
private JdbcTemplate jdbcTemplate;
private static final org.slf4j.Logger LOGGER = org.slf4j.LoggerFactory.getLogger(ExtractSqlSample.class);
@Autowired
private final SqlQueryLoader sqlQueryLoader;
private static Map<String, String> sqlQueryMap;
private Integer errorCode = 0;
private String sqlState = "";
@PostConstruct
public void initialize() throws Exception {
sqlQueryMap = sqlQueryLoader.loadResource(AppConstants.EXTRACTED_SQL_BASE_PATH + AppConstants.EXTRACT_SQL_SAMPLE);
}
@Autowired
public ExtractSqlSample(SqlQueryLoader sqlQueryLoader) {
this.sqlQueryLoader = sqlQueryLoader;
}
@Override
public void spExtractSqlSample(BigDecimal id)
throws GeneralException {
try {
Map<String, Object> resMap;
BigDecimal v1 = null;
String v2 = null;
jdbcTemplate.update(sqlQueryMap.get("extractSqlSample.spExtractSqlSample"));
resMap = jdbcTemplate.queryForMap(sqlQueryMap.get("extractSqlSample.spExtractSqlSample2"), id);
v1 = QueryUtility.toObject(resMap.get("col1"), BigDecimal.class );
v2 = QueryUtility.toObject(resMap.get("col2"), String.class );
}
catch (Exception e) {
throw new GeneralException(e, LOGGER);
}
}
}
public class AppConstants {
public static final String EXTRACTED_SQL_BASE_PATH = "src/main/resources/sql";
public static final String EXTRACT_SQL_SAMPLE = "/ExtractSqlSample.sql";
}
<queries> <query name="extractSqlSample.spExtractSqlSample"> insert into tab1 values (1, 'text1') </query> <query name="extractSqlSample.spExtractSqlSample2"> select col1, col2 from tab1 where col1 = ? </query> </queries> |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: ISPIRER_PACKAGE
Please note: the option works only for the Oracle, SQL Server, Sybase ASE and Sybase ASA sources!
By default, Ispirer Toolkit generates utility classes in the com.ispirer.<source_db_name> package, but the package name can be changed by specifying the required name in the ISPIRER_PACKAGE option.
The example below shows the difference in conversion using the ISPIRER_PACKAGE option with the default value and the changed value.
| Oracle source code | Converted to Java code by ISPIRER_PACKAGE=com.ispirer. {source_macro} | Converted to Java code with the ISPIRER_PACKAGE=com.example.pkg option |
|---|---|---|
CREATE PROCEDURE ISPIRER_PACKAGE_EXAMPLE AS str varchar2(50); BEGIN str := INITCAP(name); END; | import com.ispirer.oracle.exception.GeneralException;
import com.ispirer.oracle.lang.Plsqlutils;
public class IspirerPackageExample {
private static final org.slf4j.Logger LOGGER = org.slf4j.LoggerFactory.getLogger(IspirerPackageExample.class);
public void spIspirerPackageExample() throws GeneralException {
try {
String str = null;
str = Plsqlutils.initcap(name);
}
catch (Exception e) {
throw new GeneralException(e, LOGGER);
}
}
}
| import com.example.pkg.exception.GeneralException;
import com.example.pkg.lang.Plsqlutils;
public class IspirerPackageExample {
private static final org.slf4j.Logger LOGGER = org.slf4j.LoggerFactory.getLogger(IspirerPackageExample.class);
public void spIspirerPackageExample() throws GeneralException {
try {
String str = null;
str = Plsqlutils.initcap(name);
}
catch (Exception e) {
throw new GeneralException(e, LOGGER);
}
}
}
|
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: SECURITY_DEFINER
The example below shows the difference between the resulting procedure in both cases. Please compare:
| Oracle source code | Converted to PostgreSQL code by default | Converted to PostgreSQL code with the SECURITY_DEFINER=Yes option |
|---|---|---|
CREATE Procedure Pr_Test(p1 int default 0,p2 int, p3 int ) IS BEGIN insert into tab4 (col1, col2, col3) select p1,p2,p3 from dual; END Pr_Test; | CREATE OR REPLACE Procedure Pr_Test(p1 INTEGER default 0,p2 INTEGER DEFAULT NULL, p3 INTEGER DEFAULT NULL) LANGUAGE plpgsql AS $$ BEGIN insert into tab4(col1, col2, col3) select p1,p2,p3; END; $$; | CREATE OR REPLACE Procedure Pr_Test(p1 INTEGER default 0,p2 INTEGER DEFAULT NULL, p3 INTEGER DEFAULT NULL) LANGUAGE plpgsql SECURITY DEFINER AS $$ BEGIN insert into tab4(col1, col2, col3) select p1,p2,p3; END; $$; |
CREATE or replace Procedure Pr_Test(p1 int default 0,p2 int, p3 int ) IS BEGIN insert into tab4 (col1, col2, col3) select p1,p2,p3 from dual; commit; insert into tab4 (col1, col2, col3) select 11110,p2,p3 from dual; rollback; END Pr_Test; | CREATE or replace Procedure Pr_Test(p1 INTEGER default 0,p2 INTEGER DEFAULT NULL, p3 INTEGER DEFAULT NULL) LANGUAGE plpgsql AS $$ BEGIN insert into tab4(col1, col2, col3) select p1,p2,p3; COMMIT; insert into tab4(col1, col2, col3) select 11110,p2,p3; ROLLBACK; END; $$; | CREATE or replace Procedure Pr_Test(p1 INTEGER default 0,p2 INTEGER DEFAULT NULL, p3 INTEGER DEFAULT NULL) LANGUAGE plpgsql SECURITY DEFINER AS $$ BEGIN insert into tab4(col1, col2, col3) select p1,p2,p3; -- COMMIT insert into tab4(col1, col2, col3) select 11110,p2,p3; -- rollback END; $$; |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: TRIG_PROC_SCHEMA_PREFIX and TRIG_PROC_SCHEMA_SUFFIX
The example below shows the difference in the resulting procedure in both cases.
[POSTGRE]
TRIG_PROC_SCHEMA_PREFIX=Prefix_
TRIG_PROC_SCHEMA_SUFFIX=_Suffix
Please compare:
| Informix source code | Converted PostgreSQL code (by default) | Converted PostgreSQL code (with options set) |
|---|---|---|
create procedure schm.tr_proc_print() referencing new as n for my_table ; DEFINE v_message VARCHAR(255); LET v_message = 'Nailed it!'; end procedure ; create trigger schm.tr_proc insert on schm.my_table referencing new as new for each row (execute procedure schm.tr_proc_print() with trigger references ); | CREATE OR REPLACE FUNCTION schm.tr_proc_print_trfunc() RETURNS TRIGGER LANGUAGE plpgsql AS $$ DECLARE v_message VARCHAR(255); BEGIN v_message := 'Nailed it!'; RETURN NULL; END; $$; create trigger tr_proc AFTER insert on schm.my_table for each row EXECUTE PROCEDURE schm.tr_proc_print_trfunc(); | CREATE SCHEMA IF NOT EXISTS Prefix_schm_Suffix; CREATE OR REPLACE FUNCTION Prefix_schm_Suffix.tr_proc_print_trfunc() RETURNS TRIGGER LANGUAGE plpgsql AS $$ DECLARE v_message VARCHAR(255); BEGIN v_message := 'Nailed it!'; RETURN NULL; END; $$; create trigger tr_proc AFTER insert on schm.my_table for each row EXECUTE PROCEDURE Prefix_schm_Suffix.tr_proc_print_trfunc(); |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: BCP_COMMAND_LINE_CUSTOM_PARAMETERS
Here is an example of using the option [SYBASE] BCP_COMMAND_LINE_CUSTOM_PARAMETERS
| BCP command line by default | BCP command line with the option value changed |
|---|---|
ini: [SYBASE] BCP_COMMAND_LINE_CUSTOM_PARAMETERS=-J iso_1 sh: <...> /sybase/PC/OCS-16_0/bin/bcp custom..TABLE1 in table1.txt -c -t!^ -r#^ -e table1.err -U ***** -P ***** -S PC -b1000 -J iso_1 <...> | ini: [SYBASE] BCP_COMMAND_LINE_CUSTOM_PARAMETERS=-J utf8 -m1000 sh: <...> /sybase/PC/OCS-16_0/bin/bcp custom..TABLE1 in table1.txt -c -t!^ -r#^ -e table1.err -U ***** -P ***** -S PC -b1000 -J utf8 -m1000 <...> |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: USE_DOUBLE
Please note: the option works only for the Oracle to Java direction!
By default, Ispirer Toolkit converts NUMBER with non-zero precision and with scale greater 18 to BigDecimal, but if USE_DOUBLE is set to “yes”, the tool converts NUMBER to Double.
The example below shows the difference between the default conversion and the conversion using the USE_DOUBLE=yes option.
| Oracle source code | Converted to Java code by default | Converted to Java code with the USE_DOUBLE=yes option |
|---|---|---|
declare v1 number := 60; v2 number(5, 2) := 50; v3 number(19); v4 number(7) := 15; begin v3 := v1 * v2; v3 := v3 + v4; end; | BigDecimal v1 = new BigDecimal("60");
BigDecimal v2 = new BigDecimal("50");
BigDecimal v3 = null;
Integer v4 = 15;
v3 = v1.multiply(v2);
v3 = v3.add(BigDecimal.valueOf(v4));
| Double v1 = 60d; Double v2 = 50d; Double v3 = null; Integer v4 = 15; v3 = v1 * v2; v3 = v3 + v4; |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: COMMIT_EACH_METHOD
Please note: the option works only for the Oracle to Java, SQL Server to Java, Sybase ASE to Java, Sybase ASA to Java directions!
By default, Ispirer Toolkit adds a commit at the end of each method, but if the option is set to “No”, the tool doesn't add a commit to methods.
The example below shows the difference between the default conversion and the conversion using the COMMIT_EACH_METHOD=no option.
| Oracle source code | Converted to Java code by default | Converted to Java code with the COMMIT_EACH_METHOD=No option |
|---|---|---|
CREATE PROCEDURE PROC_DELETE_EMPLOYEE
IS
BEGIN
DELETE EMPLOYEE;
END;
| public void spProcDeleteEmployee() throws SQLException, GeneralException {
Connection mConn = JDBCDataSource.getConnection();
try {
try(PreparedStatement mStmt = mConn.prepareStatement("DELETE EMPLOYEE");) {
SQLCursorHandler.getInstance().setRowcount(mStmt.executeUpdate());
}
catch (SQLException se) {
SQLCursorHandler.getInstance().handleExeption(se);
throw se;
}
if (!mConn.getAutoCommit()) {
mConn.commit();
}
}
catch (Exception e) {
throw new GeneralException(e, LOGGER);
}
finally {
if (mConn != null) {
mConn.close();
}
}
}
| public void spProcDeleteEmployee() throws SQLException, GeneralException {
Connection mConn = JDBCDataSource.getConnection();
try {
try(PreparedStatement mStmt = mConn.prepareStatement("DELETE EMPLOYEE");) {
SQLCursorHandler.getInstance().setRowcount(mStmt.executeUpdate());
}
catch (SQLException se) {
SQLCursorHandler.getInstance().handleExeption(se);
throw se;
}
}
catch (Exception e) {
throw new GeneralException(e, LOGGER);
}
finally {
if (mConn != null) {
mConn.close();
}
}
}
|
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: ORACLE_USE_PREPROCESSOR
Please note: the option works only for the source Oracle database!
By default, Ispirer Toolkit does not precompile objects when using conditional compilation with the $IF directive. But if ORACLE_USE_PREPROCESSOR is set to “yes”, the tool performs precompilation to obtain the object body without the $if directive before converting objects.
| Oracle source code | Converted to PostgreSQL code by default | Converted to PostgreSQL code with the ORACLE_USE_PREPROCESSOR =No option |
|---|---|---|
create or replace function FN_COND_COMPIL_NESTED return varchar2 is begin $IF PKG_COND_COMPIL_NESTED_2.G_true $THEN return 'YES!'; $ELSE return 'NO!'; $END end FN_COND_COMPIL_NESTED; | CREATE OR REPLACE FUNCTION FN_COND_COMPIL_NESTED() RETURNS VARCHAR LANGUAGE plpgsql AS $$ BEGIN /* Ispirer comment - Conditional Compilation Directives are not supported. $IF PKG_COND_COMPIL_NESTED_2.G_true $THEN */ return 'YES!'; /* Ispirer comment - Conditional Compilation Directives are not supported. $ELSE */ return 'NO!'; /* Ispirer comment - Conditional Compilation Directives are not supported. $END */ END; $$; | CREATE OR REPLACE FUNCTION FN_COND_COMPIL_NESTED() RETURNS VARCHAR LANGUAGE plpgsql AS $$ BEGIN return 'YES!'; END; $$; |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: CONV_ALL_PROC_TO_FUNC
Here is an example of using the option CONV_ALL_PROC_TO_FUNC.
| MSSQL source code | Converted to PostgreSQL code by default | Converted to PostgreSQL code with the CONV_ALL_PROC_TO_FUNC =Yes option |
|---|---|---|
create PROCEDURE [dbo].[sp_tab_insert] @id int, @name varchar(10) AS insert into t3 values (@id, @name) | create or replace PROCEDURE sp_tab_insert(v_id INTEGER, v_name VARCHAR) LANGUAGE plpgsql AS $$ BEGIN insert into T3 values(v_id, v_name); END; $$; | create or replace FUNCTION sp_tab_insert(v_id INTEGER, v_name VARCHAR) RETURNS VOID LANGUAGE plpgsql AS $$ BEGIN insert into T3 values(v_id, v_name); RETURN; END; $$; |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: USE_INDEX_NAMES
The example below shows the difference in the resulting procedure in both cases. Please compare:
| MSSQL source code | Converted to PostgreSQL code by default | Converted to PostgreSQL code with the USE_INDEX_NAMES=No option |
|---|---|---|
CREATE INDEX index1 ON dbo.t_index1 (col1 ASC); CREATE UNIQUE INDEX index2 ON dbo.t_index1 (col1 ASC, col2 ASC); | CREATE INDEX index1 ON t_index1 (col1 ASC); CREATE UNIQUE INDEX index2 ON t_index1 (col1 ASC, col2 ASC); | CREATE INDEX ON t_index1 (col1 ASC); CREATE UNIQUE INDEX ON t_index1 (col1 ASC, col2 ASC); |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: CASE_INSENS_DATA
The example below shows the difference in the resulting procedure in the DEFAULT and COLLATION cases. Please compare:
| Type / Option Value | Code sample |
|---|---|
| MSSQL source | create table tb_collation ( first_name varchar(64), last_name varchar(64) ); create procedure pr_collation @title varchar(20) = 'ispirer' as BEGIN declare @title2 varchar(20) = 'ISPIRER' IF (@title = @title2) begin print 'equal' END IF (@title like @title2 ) begin print 'like' END END |
| PostgreSQL CASE_INSENS_DATA=Default | create table tb_collation ( first_name VARCHAR(64), last_name VARCHAR(64) ); create or replace PROCEDURE pr_collation (v_title VARCHAR DEFAULT 'ispirer')
LANGUAGE plpgsql
AS $$
DECLARE
v_title2 VARCHAR(20) DEFAULT 'ISPIRER';
BEGIN
IF (v_title = v_title2) then
RAISE NOTICE 'equal';
end if;
IF (v_title ilike v_title2) then
RAISE NOTICE 'like';
end if;
END; $$;
|
| PostgreSQL CASE_INSENS_DATA=Collation | CREATE COLLATION IF NOT EXISTS swcol_ci_nondet (provider = icu, locale = 'und-u-ks-level2', deterministic = false); CREATE COLLATION IF NOT EXISTS swcol_ci_det (provider = icu, locale = 'und-u-ks-level2', deterministic = true); create table tb_collation ( first_name VARCHAR(64) COLLATE swcol_ci_nondet, last_name VARCHAR(64) COLLATE swcol_ci_nondet ); create or replace PROCEDURE pr_collation(v_title VARCHAR DEFAULT 'ispirer')
LANGUAGE plpgsql
AS $$
DECLARE
v_title2 VARCHAR(20) COLLATE swcol_ci_nondet DEFAULT 'ISPIRER';
BEGIN
IF (v_title COLLATE swcol_ci_nondet = v_title2) then
RAISE NOTICE 'equal';
end if;
IF (v_title ilike v_title2 COLLATE swcol_ci_det) then
RAISE NOTICE 'like';
end if;
END; $$;
|
| PostgreSQL CASE_INSENS_DATA=Lower | create table tb_collation ( first_name VARCHAR(64), last_name VARCHAR(64) ); create or replace PROCEDURE pr_collation(v_title VARCHAR DEFAULT 'ispirer')
LANGUAGE plpgsql
AS $$
DECLARE
v_title2 VARCHAR(20) DEFAULT 'ISPIRER';
BEGIN
IF (LOWER(v_title) = LOWER(v_title2)) then
RAISE NOTICE 'equal';
end if;
IF (v_title ilike v_title2) then
RAISE NOTICE 'like';
end if;
END; $$;
|
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: RESOLVE_PARAMETER_NAME_AMBIGUITY
The example below shows the difference in the resulting procedure in both cases. Please compare:
| Informix source code | PostgreSQL RESOLVE_PARAMETER_NAME_AMBIGUITY =No | PostgreSQL RESOLVE_PARAMETER_NAME_AMBIGUITY =Yes |
|---|---|---|
CREATE PROCEDURE sp_table_ambiguity (col1 integer, col2 integer, col3 integer) DEFINE var_expr1 INTEGER; DEFINE var_expr2 INTEGER; SELECT table1.col1, col3 INTO var_expr1, var_expr2 FROM table1 WHERE table1.col2 = col1 LIMIT 1; END PROCEDURE | CREATE OR REPLACE PROCEDURE sp_table_ambiguity(col1 INTEGER, col2 INTEGER, col3 INTEGER) LANGUAGE plpgsql AS $$ DECLARE var_expr1 INTEGER; var_expr2 INTEGER; BEGIN SELECT table1.col1, col3 INTO var_expr1,var_expr2 FROM table1 WHERE table1.col2 = col1 LIMIT 1; END; $$; | CREATE OR REPLACE PROCEDURE sp_table_ambiguity(col1 INTEGER, col2 INTEGER, col3 INTEGER) LANGUAGE plpgsql AS $$ DECLARE var_expr1 INTEGER; var_expr2 INTEGER; BEGIN SELECT table1.col1, sp_table_ambiguity.col3 INTO var_expr1,var_expr2 FROM table1 WHERE table1.col2 = sp_table_ambiguity.col1 LIMIT 1; END; $$; |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: USE_CUSTOM_CAST_DATE_INT
The example below shows the difference in the resulting procedure in both cases. Please compare:
| Informix source code | PostgreSQL USE_CUSTOM_CAST_DATE_INT =No | PostgreSQL USE_CUSTOM_CAST_DATE_INT =Yes |
|---|---|---|
create table t_log(id integer, col1 integer, col2 integer); CREATE PROCEDURE sp_date_as_integer (ibuf INTEGERT) DEFINE res date; LET res = ibuf; LET ibuf = res; insert into t_log values (1, ibuf, res); END PROCEDURE; | create table t_log(id INTEGER, col1 INTEGER, col2 INTEGER); CREATE OR REPLACE PROCEDURE sp_date_as_integer(ibuf INTEGERT) LANGUAGE plpgsql AS $$ DECLARE res DATE; BEGIN res := CAST(ibuf AS DATE); ibuf := EXTRACT(DAY FROM(res):: TIMESTAMP -'1899-12-31':: TIMESTAMP); insert into dbm.alf_log_k values(1, ibuf, EXTRACT(DAY FROM(res):: TIMESTAMP -'1899-12-31':: TIMESTAMP)); END; $$; | create table t_log(id INTEGER, col1 INTEGER, col2 INTEGER); CREATE OR REPLACE PROCEDURE sp_date_as_integer(ibuf INTEGERT) LANGUAGE plpgsql AS $$ DECLARE res DATE; BEGIN res := CAST(ibuf AS DATE); ibuf := CAST(res AS INTEGER); insert into t_log values(1, ibuf, CAST(res AS INTEGER)); END; $$; |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: ANSINULL
Here below you can see a sample of the source code for a user-defined function with multiple arguments.
The left column contains the original code, the second column shows the converted code without the option, and the third column demonstrates the conversion results when the ANSINULL option is set to OFF.
| Source code (Sybase ASE) | Converted PostgreSQL code (without option ANSINULL or ANSINULL=ON) | Converted PostgreSQL code (with option ANSINULL=OFF) |
|---|---|---|
CREATE PROCEDURE sp_ansinull @param1 INT, @param2 INT AS BEGIN SELECT 1 WHERE @param1=@param2 END | CREATE OR REPLACE FUNCTION sp_ansinull(v_param1 INTEGER, v_param2 INTEGER)
RETURNS TABLE
(
col INTEGER
) LANGUAGE plpgsql
AS $$
BEGIN
IF v_param1 = v_param2 then
return query
select 1;
end if;
END; $$;
| CREATE OR REPLACE FUNCTION sp_ansinull(v_param1 INTEGER, v_param2 INTEGER)
RETURNS TABLE
(
col INTEGER
) LANGUAGE plpgsql
AS $$
BEGIN
IF (v_param1 IS NOT DISTINCT FROM v_param2) then
return query
select 1;
end if;
END; $$;
|
As you can see, if the ANSINULL option is not enabled (ANSINULL=OFF), the conversion ensures that NULL handling behavior in PostgreSQL matches that of Sybase ASE. This means that comparisons involving NULL values will be processed in a way that maintains compatibility with the original logic, preventing unexpected results due to differences in database behavior.
If the ANSINULL option is enabled (ANSINULL=ON), PostgreSQL’s standard NULL handling rules apply, which might lead to discrepancies in how NULL values are treated during query execution.
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: FUNC_MAX_ARGS
Here below you can see a sample of the source code for a user-defined function with multiple arguments.
The left column contains the original code, the second column shows the converted code without the option, and the third column demonstrates the conversion results when the FUNC_MAX_ARGS option is set to a custom value.
| Source code (Sybase ASE) | Converted PostgreSQL code (without option FUNC_MAX_ARGS or with option FUNC_MAX_ARGS=100/Default value) | Converted PostgreSQL code (with option FUNC_MAX_ARGS=200) |
|---|---|---|
CREATE PROCEDURE MyProc @param1 INT, @param2 INT, @param3 INT, … @param200 INT AS BEGIN SELECT 1 END | CREATE TYPE MyProc_PS AS ( v_param1 INTEGER, v_param2 INTEGER, v_param3 INTEGER, -- Add more parameters until param200 v_param200 INTEGER ); CREATE OR REPLACE FUNCTION MyProc(SWP_INPUT MyProc_PS) RETURNS TABLE (col INTEGER) LANGUAGE plpgsql AS $$ BEGIN RETURN QUERY SELECT 1; END; $$; | CREATE OR REPLACE FUNCTION MyProc( v_param1 INTEGER, v_param2 INTEGER, v_param3 INTEGER, -- Add more parameters until param200 v_param200 INTEGER) RETURNS TABLE (col INTEGER) LANGUAGE plpgsql AS $$ BEGIN RETURN QUERY SELECT 1; END; $$; |
As you can see If the FUNC_MAX_ARGS option is not specified, the default value (100) is used, allowing functions and procedures with up to 100 arguments to be converted without creating an additional type. If the option is explicitly set to a value, any functions/procedures that have more than the specified number of parameters will be converted using an additional type.
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: ENSURE_UNIQUE_INDEX_NAMES
Here below you can see a sample of the source code for index creation in Sybase ASA.
The left column contains the original code, the second column shows the converted code without the option, and the third column demonstrates the conversion results when the ENSURE_UNIQUE_INDEX_NAMES option is set to YES.
| Source code (Sybase ASA) | Converted Oracle code (without option ENSURE_UNIQUE_INDEX_NAMES or ENSURE_UNIQUE_INDEX_NAMES=No) | Converted Oracle code (with option ENSURE_UNIQUE_INDEX_NAMES=Yes) |
|---|---|---|
CREATE INDEX idx_order ON orders (order_id); CREATE INDEX idx_order ON customers (customer_id); | CREATE INDEX idx_order ON orders (order_id); -- Error: ORA-00955: name is already used by an existing object | CREATE INDEX orders_idx_order ON orders (order_id); CREATE INDEX customers_idx_order ON customers (customer_id); |
As you can see, if the ENSURE_UNIQUE_INDEX_NAMES option is not enabled (ENSURE_UNIQUE_INDEX_NAMES=No), the migration process may result in index name conflicts when multiple tables have indexes with the same name, causing errors in the target database.
When the ENSURE_UNIQUE_INDEX_NAMES option is enabled (ENSURE_UNIQUE_INDEX_NAMES=Yes), the table name is prefixed to the index name, ensuring uniqueness across all tables. This prevents conflicts and allows for a seamless migration process.
Setting ENSURE_UNIQUE_INDEX_NAMES=Yes guarantees that all indexes are successfully created in the target database without requiring manual renaming.
Conversely, if set to No, existing index names are preserved, which may lead to conflicts when duplicate index names exist across tables.
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: ORACLE CASE_INSENS_DATA
The example below shows the difference in the resulting procedure in the DEFAULT and LOWER cases. Please compare:
| MSSQL source code | ORACLE CASE_INSENS_DATA=Default | ORCALE CASE_INSENS_DATA=Lower |
|---|---|---|
CREATE TABLE test_case_ins
(
v_tit VARCHAR(20)
);
INSERT INTO test_case_ins VALUES ('Istest');
CREATE PROCEDURE SP_lower_2 @VAR VARCHAR(4000) = 'istest' AS
BEGIN
DECLARE
@VAR2 VARCHAR(20) = 'ISTEST',
@t1 int;
select @t1 = case t1.v_tit
when 'IsTest' then 1
when 'NoTEST' then 2
else 0 end
from test_case_ins t1
join test_case_ins t2 on t1.v_tit = t2.v_tit
where t1.v_tit like 'ISTEST'
or t1.v_tit in ('ISTEST','Istest')
END
| CREATE TABLE test_case_ins
(
v_tit VARCHAR2(20)
);
INSERT INTO test_case_ins VALUES ('Istest');
CREATE OR REPLACE PROCEDURE SP_lower_2(v_VAR IN varchar2 DEFAULT 'istest') as
v_VAR2 VARCHAR2(20) DEFAULT 'ISTEST';
v_t1 NUMBER(10,0);
BEGIN
select case t1.v_tit
when 'IsTest' then 1
when 'NoTEST' then 2
else 0 end INTO v_t1 from test_case_ins t1
join test_case_ins t2 on t1.v_tit = t2.v_tit where t1.v_tit like 'ISTEST'
or t1.v_tit in('ISTEST','Istest') FETCH FIRST 1 ROWS ONLY;
EXCEPTION
WHEN NO_DATA_FOUND THEN
NULL;
END;
| CREATE TABLE test_case_ins
(
v_tit VARCHAR2(20)
);
INSERT INTO test_case_ins VALUES ('Istest');
CREATE OR REPLACE PROCEDURE SP_lower_2(v_VAR IN varchar2 DEFAULT 'istest') as
v_VAR2 VARCHAR2(20) DEFAULT 'ISTEST';
v_t1 NUMBER(10,0);
BEGIN
select case LOWER(t1.v_tit)
when LOWER('IsTest') then 1
when LOWER('NoTEST') then 2
else 0 end INTO v_t1 from test_case_ins t1
join test_case_ins t2 on LOWER(t1.v_tit) = LOWER(t2.v_tit) where LOWER(t1.v_tit) like LOWER('ISTEST')
or LOWER(t1.v_tit) in(LOWER('ISTEST'),LOWER('Istest')) FETCH FIRST 1 ROWS ONLY;
EXCEPTION
WHEN NO_DATA_FOUND THEN
NULL;
END;
|
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: RECURSIVE_TRIGGERS_ENABLED
The purpose of this article is to demonstrate how the RECURSIVE_TRIGGERS_ENABLED option affects conversion results.
The following example illustrates the impact of enabling or disabling this option during trigger creation:
| Source code (MS SQL Server) | Converted PostgreSQL code (without option RECURSIVE_TRIGGERS_ENABLED or RECURSIVE_TRIGGERS_ENABLED=NO) | Converted PostgreSQL code (with option RECURSIVE_TRIGGERS_ENABLED=YES) |
|---|---|---|
create TRIGGER tr_rec_update
ON tab_for_tr
AFTER UPDATE
AS
BEGIN
update t
set b_col = UPPER(i.b_col)
from tab_for_tr t
inner join inserted i on t.a_col = i.a_col
END
| CREATE TRIGGER tr_rec_update AFTER UPDATE ON tab_for_tr REFERENCING NEW TABLE AS new_table FOR STATEMENT WHEN(pg_trigger_depth() < 1) EXECUTE PROCEDURE tr_rec_update_TrFunc(); | CREATE TRIGGER tr_rec_update AFTER UPDATE ON tab_for_tr REFERENCING NEW TABLE AS new_table FOR STATEMENT EXECUTE PROCEDURE tr_rec_update_TrFunc(); |
The RECURSIVE_TRIGGERS_ENABLED option serves the same objective as the 'Recursive triggers enabled' (or RECURSIVE_TRIGGERS) option in the MS SQL Server database. It controls recursion for triggers. The default value is NO the same as OFF of the MS SQL Server. When the option is set to NO all the triggers with direct recursion will be called once and if the option is set to YES the recursion is allowed.
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: PACKAGE_VAR_CONVERSION
The purpose of this article is to demonstrate how the PACKAGE_VAR_CONVERSION option affects conversion results. The example below shows the difference in the resulting procedure in all cases. Please compare:
| Type / Option Value | Code sample |
|---|---|
| Oracle source | CREATE OR REPLACE PACKAGE test_pkg1 IS
g_n1 number := 15;
PROCEDURE proc1;
END;
/
CREATE OR REPLACE PACKAGE BODY test_pkg1 IS
g_n2 CONSTANT NUMBER := 2026;
g_s varchar2(65) := 'ТЕСТ';
PROCEDURE print_global_vars IS
BEGIN
DBMS_OUTPUT.PUT_LINE('g_n1 = '||g_n1);
DBMS_OUTPUT.PUT_LINE('g_n2 = '||g_n2);
DBMS_OUTPUT.PUT_LINE('g_s = '||g_s);
END;
PROCEDURE proc1 IS
v_n NUMBER;
v_v varchar2(65);
BEGIN
v_n := g_n2;
if g_s = 'ТЕСТ1' then
g_s := 'aaa';
g_n1 := 1000;
else
g_s := 'bbb';
g_n1 := 2000;
end if;
v_v := g_s;
DBMS_OUTPUT.PUT_LINE('v_n = '||v_n);
DBMS_OUTPUT.PUT_LINE('v_v = '||v_v);
print_global_vars;
END;
BEGIN
DBMS_OUTPUT.PUT_LINE('Body Initialization Block');
g_s := 'ТЕСТ1';
END;
/
|
| Postgre PACKAGE_VAR_CONVERSION= | CREATE SCHEMA IF NOT EXISTS TEST_PKG1
;
DROP TYPE IF EXISTS TEST_PKG1.GL_VAR_TYPE CASCADE;
CREATE type TEST_PKG1.GL_VAR_TYPE
as(g_n1 NUMERIC,
g_n2 NUMERIC,
g_s VARCHAR(65));
CREATE OR REPLACE FUNCTION TEST_PKG1.INIT_GL_VAR()
RETURNS VOID LANGUAGE plpgsql
AS $$
DECLARE
SWV_GL_VAR TEST_PKG1.GL_VAR_TYPE;
BEGIN
CREATE TEMPORARY TABLE TEST_PKG1_GL_VAR AS SELECT(15,2026,'ТЕСТ')::TEST_PKG1.GL_VAR_TYPE AS SWV_GL_VAR_VAL;
-- begin Initialization Block
SWV_GL_VAR := TEST_PKG1.GET_GL_VAR();
RAISE NOTICE 'Body Initialization Block';
SWV_GL_VAR.G_S := 'ТЕСТ1';
CALL TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
-- end Initialization Block
RETURN;
EXCEPTION
WHEN SQLSTATE '42P07' THEN
NULL;
END; $$;
CREATE OR REPLACE FUNCTION TEST_PKG1.GET_GL_VAR()
RETURNS TEST_PKG1.GL_VAR_TYPE LANGUAGE plpgsql
AS $$
DECLARE
SWV_GL_VAR TEST_PKG1.GL_VAR_TYPE;
BEGIN
RETURN(select SWV_GL_VAR_VAL:: TEST_PKG1.GL_VAR_TYPE from TEST_PKG1_GL_VAR);
EXCEPTION
WHEN OTHERS THEN
PERFORM TEST_PKG1.INIT_GL_VAR();
RETURN(select SWV_GL_VAR_VAL:: TEST_PKG1.GL_VAR_TYPE from TEST_PKG1_GL_VAR);
END; $$;
CREATE OR REPLACE PROCEDURE TEST_PKG1.SET_GL_VAR(SWP_GLVAR TEST_PKG1.GL_VAR_TYPE)
LANGUAGE plpgsql
AS $$
BEGIN
UPDATE TEST_PKG1_GL_VAR SET SWV_GL_VAR_VAL = SWP_GLVAR;
END; $$;
CREATE OR REPLACE PROCEDURE test_pkg1.PRINT_GLOBAL_VARS()
LANGUAGE plpgsql
AS $$
DECLARE
SWV_GL_VAR TEST_PKG1.GL_VAR_TYPE DEFAULT TEST_PKG1.GET_GL_VAR();
BEGIN
RAISE NOTICE '%',CONCAT('g_n1 = ',SWV_GL_VAR.g_n1);
RAISE NOTICE '%',CONCAT('g_n2 = ',SWV_GL_VAR.g_n2);
RAISE NOTICE '%',CONCAT('g_s = ',SWV_GL_VAR.g_s);
END; $$;
CREATE OR REPLACE PROCEDURE test_pkg1.PROC1()
LANGUAGE plpgsql
AS $$
DECLARE
SWV_GL_VAR TEST_PKG1.GL_VAR_TYPE DEFAULT TEST_PKG1.GET_GL_VAR();
v_n NUMERIC;
v_v VARCHAR(65);
BEGIN
v_n := SWV_GL_VAR.g_n2;
if SWV_GL_VAR.g_s = 'ТЕСТ1' then
SWV_GL_VAR.G_S := 'aaa';
CALL TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
SWV_GL_VAR.G_N1 := 1000;
CALL TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
else
SWV_GL_VAR.G_S := 'bbb';
CALL TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
SWV_GL_VAR.G_N1 := 2000;
CALL TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
end if;
v_v := SWV_GL_VAR.g_s;
RAISE NOTICE '%',CONCAT('v_n = ',v_n);
RAISE NOTICE '%',CONCAT('v_v = ',v_v);
CALL TEST_PKG1.PRINT_GLOBAL_VARS();
SWV_GL_VAR := TEST_PKG1.GET_GL_VAR();
END; $$;
|
| Postgre PACKAGE_VAR_CONVERSION=pg_variables | CREATE SCHEMA IF NOT EXISTS TEST_PKG1
;
DROP TYPE IF EXISTS TEST_PKG1.GL_VAR_TYPE CASCADE;
CREATE type TEST_PKG1.GL_VAR_TYPE
as(g_n1 NUMERIC,
g_n2 NUMERIC,
g_s VARCHAR(65));
CREATE OR REPLACE FUNCTION TEST_PKG1.GET_GL_VAR()
RETURNS TEST_PKG1.GL_VAR_TYPE LANGUAGE plpgsql
AS $$
DECLARE
SWV_GL_VAR TEST_PKG1.GL_VAR_TYPE;
BEGIN
if not pgv_exists('TEST_PKG1','GL_VAR_TYPE') then
perform pgv_set('TEST_PKG1','GL_VAR_TYPE',(15,2026,'ТЕСТ')::TEST_PKG1.GL_VAR_TYPE);
-- begin Initialization Block
SWV_GL_VAR := TEST_PKG1.GET_GL_VAR();
RAISE NOTICE 'Body Initialization Block';
SWV_GL_VAR.G_S := 'ТЕСТ1';
PERFORM TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
-- end Initialization Block
end if;
return(select pgv_get('TEST_PKG1','GL_VAR_TYPE',NULL:: TEST_PKG1.GL_VAR_TYPE));
END; $$;
CREATE OR REPLACE FUNCTION TEST_PKG1.SET_GL_VAR(SWP_GLVAR TEST_PKG1.GL_VAR_TYPE)
RETURNS VOID LANGUAGE plpgsql
AS $$
BEGIN
perform pgv_set('TEST_PKG1','GL_VAR_TYPE',SWP_GLVAR);
END; $$;
CREATE OR REPLACE PROCEDURE test_pkg1.PRINT_GLOBAL_VARS()
LANGUAGE plpgsql
AS $$
DECLARE
SWV_GL_VAR TEST_PKG1.GL_VAR_TYPE DEFAULT TEST_PKG1.GET_GL_VAR();
BEGIN
RAISE NOTICE '%',CONCAT('g_n1 = ',SWV_GL_VAR.g_n1);
RAISE NOTICE '%',CONCAT('g_n2 = ',SWV_GL_VAR.g_n2);
RAISE NOTICE '%',CONCAT('g_s = ',SWV_GL_VAR.g_s);
END; $$;
CREATE OR REPLACE PROCEDURE test_pkg1.PROC1()
LANGUAGE plpgsql
AS $$
DECLARE
SWV_GL_VAR TEST_PKG1.GL_VAR_TYPE DEFAULT TEST_PKG1.GET_GL_VAR();
v_n NUMERIC;
v_v VARCHAR(65);
BEGIN
v_n := SWV_GL_VAR.g_n2;
if SWV_GL_VAR.g_s = 'ТЕСТ1' then
SWV_GL_VAR.G_S := 'aaa';
PERFORM TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
SWV_GL_VAR.G_N1 := 1000;
PERFORM TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
else
SWV_GL_VAR.G_S := 'bbb';
PERFORM TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
SWV_GL_VAR.G_N1 := 2000;
PERFORM TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
end if;
v_v := SWV_GL_VAR.g_s;
RAISE NOTICE '%',CONCAT('v_n = ',v_n);
RAISE NOTICE '%',CONCAT('v_v = ',v_v);
CALL TEST_PKG1.PRINT_GLOBAL_VARS();
SWV_GL_VAR := TEST_PKG1.GET_GL_VAR();
END; $$;
|
| Postgre PACKAGE_VAR_CONVERSION= session_config_params | CREATE SCHEMA IF NOT EXISTS TEST_PKG1
;
DROP TYPE IF EXISTS TEST_PKG1.GL_VAR_TYPE CASCADE;
CREATE type TEST_PKG1.GL_VAR_TYPE
as(g_n1 NUMERIC,
g_n2 NUMERIC,
g_s VARCHAR(65));
CREATE OR REPLACE FUNCTION TEST_PKG1.GET_GL_VAR()
RETURNS TEST_PKG1.GL_VAR_TYPE LANGUAGE plpgsql
AS $$
DECLARE
SWV_GL_VAR TEST_PKG1.GL_VAR_TYPE;
BEGIN
RETURN current_setting('sqlways.TEST_PKG1_GL_VAR'):: TEST_PKG1.GL_VAR_TYPE;
EXCEPTION
WHEN SQLSTATE '42704' THEN
SET sqlways.TEST_PKG1_GL_VAR = DEFAULT;
PERFORM set_config('sqlways.TEST_PKG1_GL_VAR',(15,2026,'ТЕСТ')::TEST_PKG1.GL_VAR_TYPE::text,
false);
-- begin Initialization Block
SWV_GL_VAR := TEST_PKG1.GET_GL_VAR();
RAISE NOTICE 'Body Initialization Block';
SWV_GL_VAR.G_S := 'ТЕСТ1';
PERFORM TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
-- end Initialization Block
RETURN current_setting('sqlways.TEST_PKG1_GL_VAR'):: TEST_PKG1.GL_VAR_TYPE;
END; $$;
CREATE OR REPLACE FUNCTION TEST_PKG1.SET_GL_VAR(SWP_GLVAR TEST_PKG1.GL_VAR_TYPE)
RETURNS VOID LANGUAGE plpgsql
AS $$
BEGIN
perform set_config('sqlways.TEST_PKG1_GL_VAR',SWP_GLVAR::text,false);
END; $$;
CREATE OR REPLACE PROCEDURE test_pkg1.PRINT_GLOBAL_VARS()
LANGUAGE plpgsql
AS $$
DECLARE
SWV_GL_VAR TEST_PKG1.GL_VAR_TYPE DEFAULT TEST_PKG1.GET_GL_VAR();
BEGIN
RAISE NOTICE '%',CONCAT('g_n1 = ',SWV_GL_VAR.g_n1);
RAISE NOTICE '%',CONCAT('g_n2 = ',SWV_GL_VAR.g_n2);
RAISE NOTICE '%',CONCAT('g_s = ',SWV_GL_VAR.g_s);
END; $$;
CREATE OR REPLACE PROCEDURE test_pkg1.PROC1()
LANGUAGE plpgsql
AS $$
DECLARE
SWV_GL_VAR TEST_PKG1.GL_VAR_TYPE DEFAULT TEST_PKG1.GET_GL_VAR();
v_n NUMERIC;
v_v VARCHAR(65);
BEGIN
v_n := SWV_GL_VAR.g_n2;
if SWV_GL_VAR.g_s = 'ТЕСТ1' then
SWV_GL_VAR.G_S := 'aaa';
PERFORM TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
SWV_GL_VAR.G_N1 := 1000;
PERFORM TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
else
SWV_GL_VAR.G_S := 'bbb';
PERFORM TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
SWV_GL_VAR.G_N1 := 2000;
PERFORM TEST_PKG1.SET_GL_VAR(SWV_GL_VAR);
end if;
v_v := SWV_GL_VAR.g_s;
RAISE NOTICE '%',CONCAT('v_n = ',v_n);
RAISE NOTICE '%',CONCAT('v_v = ',v_v);
CALL TEST_PKG1.PRINT_GLOBAL_VARS();
SWV_GL_VAR := TEST_PKG1.GET_GL_VAR();
END; $$;
|
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: AUTO_FUNCTION_VOLATILITY
The example below shows the difference in the resulting function in both cases. Please compare and try:
| Infromix (source) | PostgreSQL (without option AUTO_FUNCTION_VOLATILITY or AUTO_FUNCTION_VOLATILITY=No) | PostgreSQL (with option AUTO_FUNCTION_VOLATILITY=Yes) |
|---|---|---|
create function fn_immutable (param int) returning int; return param * 5; end function; create function fn_stable (param int) returning date, char(30); return current year to day, 'The best day'; end function; | create or replace function fn_immutable(param integer) returns integer language plpgsql as $$ begin return param*5; end; $$; create or replace function fn_stable(param integer) returns table ( unnamed_col_1 date, unnamed_col_2 char(30) ) language plpgsql as $$ begin return query(select current_date,'The best day':: char(30)); end; $$; | create or replace function fn_immutable(param integer) returns integer IMMUTABLE language plpgsql as $$ begin return param*5; end; $$; create or replace function fn_stable(param integer) returns table ( unnamed_col_1 date, unnamed_col_2 char(30) ) STABLE language plpgsql as $$ begin return query(select current_date,'The best day':: char(30)); end; $$; |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: MERGE_DB_AND_SCHEMA
The example below shows the difference in the resulting function in both cases. Please compare and try:
| MSSQL (source) | ORACLE (without option MERGE_DB_AND_SCHEMA or MERGE_DB_AND_SCHEMA=No) | ORACLE (with option MERGE_DB_AND_SCHEMA=Yes) |
|---|---|---|
create view dbo.merge_1 as select itest.dbo.merge_test1.col1 from itest.dbo.merge_test1 join etest.dbo.tb_merge t2 on t2.col1 = itest.dbo.merge_test1.col1 join dbo.tb_merge t3 on t3.col1 = itest.dbo.merge_test1.col1 join tb_merge t4 on t4.col1 = itest.dbo.merge_test1.col1 | create or replace view dbo.merge_1(col1) as select itest.merge_test1.col1 from itest.merge_test1 join etest.tb_merge t2 on t2.col1 = itest.merge_test1.col1 join dbo.tb_merge t3 on t3.col1 = itest.merge_test1.col1 join dbo.tb_merge t4 on t4.col1 = itest.merge_test1.col1 | create or replace view etest_dbo.merge_1(col1) as select itest_dbo.merge_test1.col1 from itest_dbo.merge_test1 join etest_dbo.tb_merge t2 on t2.col1 = itest_dbo.merge_test1.col1 join etest_dbo.tb_merge t3 on t3.col1 = itest_dbo.merge_test1.col1 join etest_dbo.tb_merge t4 on t4.col1 = itest_dbo.merge_test1.col1 |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: EXPLICIT_COLUMN_OWNERSHIP
The example below shows the difference in the resulting function in both cases. Please compare and try:
| Informix (source) | PostgreSQL EXPLICIT_COLUMN_OWNERSHIP=No) | PostgreSQL (EXPLICIT_COLUMN_OWNERSHIP=Yes) |
|---|---|---|
CREATE PROCEDURE sp_1 (par1 integer) DEFINE var1, var2 INTEGER; SELECT col1t1, col1t2 INTO var1, var2 FROM table1, OUTER table2 WHERE col1t1 = col1t2 AND col2t1 = par1 LIMIT 1; END PROCEDURE | CREATE OR REPLACE PROCEDURE sp_1(par1 INTEGER) LANGUAGE plpgsql AS $$ DECLARE var1 INTEGER; var2 INTEGER; BEGIN SELECT col1t1, col1t2 INTO var1,var2 FROM table1 LEFT OUTER JOIN table2 ON col1t1 = col1t2 WHERE col2t1 = par1 LIMIT 1; END; $$; | CREATE OR REPLACE PROCEDURE sp_1(par1 INTEGER) LANGUAGE plpgsql AS $$ DECLARE var1 INTEGER; var2 INTEGER; BEGIN SELECT table1.col1t1, table2.col1t2 INTO var1,var2 FROM table1 LEFT OUTER JOIN table2 ON table1.col1t1 = table2.col1t2 WHERE table1.col2t1 = par1 LIMIT 1; END; $$; |
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: ANALYZE_TEMP_STATS
The purpose of this article is to demonstrate how the ANALYZE_TEMP_STATS option affects conversion results.
Below, you can see a sample of the source code with temporary tables and indexes. The left column contains the source Sybase ASE code, the second column shows the converted PostgreSQL code without the option, and the third column demonstrates the conversion results when the ANALYZE_TEMP_STATS option is enabled.
| Source code (Sybase ASE) | Converted PostgreSQL code by default | Converted PostgreSQL code (with option ANALYZE_TEMP_STATS=Yes) |
|---|---|---|
CREATE PROCEDURE test_proc
AS
BEGIN
CREATE TABLE #temp3 (id INT, name VARCHAR(50))
CREATE INDEX idx_temp3_id ON #temp3 (id)
INSERT INTO #temp3
SELECT id, name
FROM regular_table
WHERE status = 'ACTIVE'
INSERT INTO #temp3 VALUES (101, 'AnotherRow')
INSERT INTO regular_table
SELECT id, name, 'Val6', 'ACTIVE'
FROM #temp3
WHERE id = 1
CREATE INDEX idx_temp3_name ON #temp3 (name)
CREATE UNIQUE INDEX idx_temp3_name ON #temp3 (name)
INSERT INTO #temp3 VALUES (101, 'AnotherRow')
INSERT INTO #temp3 VALUES (102, 'AnotherRow')
INSERT INTO #temp3 VALUES (103, 'AnotherRow')
END
| CREATE OR REPLACE FUNCTION test_proc()
RETURNS TABLE
(
id INTEGER,
name VARCHAR
) LANGUAGE plpgsql
AS $$
BEGIN
CREATE TEMPORARY TABLE tt_TEMP3
(
id INTEGER,
name VARCHAR(50)
) ON COMMIT DROP;
CREATE INDEX idx_temp3_id ON tt_TEMP3
(id);
INSERT INTO tt_TEMP3
SELECT id, name
FROM regular_table
WHERE status = 'ACTIVE';
INSERT INTO tt_TEMP3 VALUES(101, 'AnotherRow');
INSERT INTO regular_table
SELECT id, name, 'Val6', 'ACTIVE'
FROM tt_TEMP3
WHERE id = 1;
CREATE INDEX idx_temp3_name ON tt_TEMP3
(name);
CREATE UNIQUE INDEX idx_temp3_name ON tt_TEMP3
(name);
INSERT INTO tt_TEMP3 VALUES(101, 'AnotherRow');
INSERT INTO tt_TEMP3 VALUES(102, 'AnotherRow');
INSERT INTO tt_TEMP3 VALUES(103, 'AnotherRow');
RETURN;
END; $$;
| CREATE OR REPLACE FUNCTION test_proc()
RETURNS TABLE
(
id INTEGER,
name VARCHAR
) LANGUAGE plpgsql
AS $$
BEGIN
CREATE TEMPORARY TABLE tt_TEMP3
(
id INTEGER,
name VARCHAR(50)
) ON COMMIT DROP;
CREATE INDEX idx_temp3_id ON tt_TEMP3
(id);
ANALYZE tt_TEMP3;
INSERT INTO tt_TEMP3
SELECT id, name
FROM regular_table
WHERE status = 'ACTIVE';
INSERT INTO tt_TEMP3 VALUES(101, 'AnotherRow');
ANALYZE tt_TEMP3;
INSERT INTO regular_table
SELECT id, name, 'Val6', 'ACTIVE'
FROM tt_TEMP3
WHERE id = 1;
CREATE INDEX idx_temp3_name ON tt_TEMP3
(name);
CREATE UNIQUE INDEX idx_temp3_name ON tt_TEMP3
(name);
ANALYZE tt_TEMP3;
INSERT INTO tt_TEMP3 VALUES(101, 'AnotherRow');
INSERT INTO tt_TEMP3 VALUES(102, 'AnotherRow');
INSERT INTO tt_TEMP3 VALUES(103, 'AnotherRow');
ANALYZE tt_TEMP3;
RETURN;
END; $$;
|
If the ANALYZE_TEMP_STATS option is not specified, the default value (No) is used, meaning that no additional ANALYZE statements are added during the conversion process.
If the option is explicitly enabled (Yes), then ANALYZE statements will be automatically inserted after index creation and INSERT operations on temporary tables, ensuring that the PostgreSQL optimizer works with fresh statistics when executing subsequent queries.
If this option does not work as expected, please contact our technical team: support@ispirer.com
[Usage example]: RETURN_TABLE_SQL_MACRO
By default, IspirerToolkit converts table-returning functions to pipelined ones.
But starting with Oracle 21c, we can use SQL_MACRO functionality.
Useful link: https://docs.oracle.com/en/database/oracle/oracle-database/21/lnpls/sql_macro-clause.html
The example below shows the difference in how the resulting table is returned in both cases.
| Source code (MS SQL Server) | Converted Oracle code by default | Converted Oracle code version 21+ and option RETURN_TABLE_SQL_MACRO=Yes |
|---|---|---|
CREATE PROCEDURE dbo.usp_GetBbeInfoById @ApplicationId BIGINT AS BEGIN DECLARE @HasBbe TINYINT, @IdNumeric NUMERIC(18, 0); SET @IdNumeric = CAST(@ApplicationId AS NUMERIC(18, 0)); SELECT TOP 1 @HasBbe = QueryOption FROM dbo.KkbApplications WITH (NOLOCK) WHERE Id = @IdNumeric ORDER BY Id DESC; SELECT CASE WHEN @HasBbe IS NULL THEN -1 ELSE 999 END AS BbeInfo; END; | CREATE OR REPLACE PROCEDURE usp_GetBbeInfoById(v_ApplicationId IN NUMBER) as
v_refcur SYS_REFCURSOR;
v_HasBbe NUMBER(3,0);
v_IdNumeric NUMBER(18,0);
BEGIN
v_IdNumeric := v_ApplicationId;
begin
SELECT * INTO v_HasBbe FROM(SELECT QueryOption FROM KkbApplications WHERE Id = v_IdNumeric ORDER BY Id DESC NULLS LAST) WHERE ROWNUM <= 1;
EXCEPTION
WHEN NO_DATA_FOUND THEN
NULL;
end;
open v_refcur for SELECT CASE WHEN v_HasBbe IS NULL THEN -1 ELSE 999 END AS BbeInfo from dual;
dbms_sql.return_result(v_refcur);
END;
| CREATE OR REPLACE FUNCTION usp_GetBbeInfoById(v_ApplicationId IN NUMBER)
RETURN VARCHAR2 SQL_MACRO(TABLE)
IS
v_HasBbe NUMBER(3,0);
v_IdNumeric NUMBER(18,0);
BEGIN
v_IdNumeric := v_ApplicationId;
BEGIN
SELECT * INTO v_HasBbe
FROM (
SELECT QueryOption
FROM KkbApplications
WHERE Id = v_IdNumeric
ORDER BY Id DESC NULLS LAST
)
WHERE ROWNUM <= 1;
EXCEPTION
WHEN NO_DATA_FOUND THEN
NULL;
END;
RETURN q'{
SELECT
CASE
WHEN }' || DBMS_ASSERT.ENQUOTE_LITERAL(v_HasBbe) || q'{ IS NULL THEN -1
ELSE 999
END AS BbeInfo
}';
END;
|
If this option does not work as expected, please contact our technical team: support@ispirer.com