Table of Contents
Ispirer Website
Ispirer Toolkit Overview
Free Trial
SQLWays ⬝ Migrating cross-database references
Approaches
As you know, PostgreSQL, unlike Sybase and MS SQL Server, does not support native cross-database references.
When planning a migration, there are several possible approaches to handling databases that are referenced across database boundaries:
- Migrating the source databases as separate databases on a single PostgreSQL instance or on multiple instances
- Merging multiple databases into a single PostgreSQL database while preserving separation at the schema level
- Merging multiple databases into a single PostgreSQL database and a single schema
- Leaving one or more databases in Sybase for the time being and addressing cross-database dependencies at the application or integration level
All of these approaches can be implemented or customized depending on specific requirements and constraints. The choice of strategy largely depends on architectural, operational, and business considerations.
In practice, approaches #2 and #3 are the most commonly adopted.
Identification and reporting of cross-database references
During the assessment or conversion phases, the Ispirer Toolkit handles cross-database references as follows:
- The InsightWays tool does not explicitly collect or report information about cross-database references.
- SQLWays converts such references implicitly and does not highlight them as a separate category.
Level of automated conversion
The InsightWays report does not assign an explicit ranking to cross-database dependencies. However, based on practical experience, these dependencies should be considered high-complexity items.
When a database-merging approach is selected, these dependencies typically allow for approximately 50% automated conversion, with the remaining effort requiring manual intervention.
Recommended best practices for handling cross-database dependencies in PostgreSQL
Regardless of the chosen migration approach, it is strongly recommended to review all code generated by the tool. Information on how to do this can be found here.
In some cases, cross-database references may not be identified correctly. In such situations, manual corrections or tool customizations may be required.
It is also important to note that the tool does not have a straightforward way to retrieve the definition of a referenced object if that object resides in another database. As a result, issues such as data type incompatibilities or missing REFCURSOR OUT parameters in procedure calls may occur.
These issues should be identified during validation and resolved through targeted manual fixes.
Relevant configuration options and features
Migrating cross-database references typically involves adjusting a specific set of conversion parameters. These parameters help align the converted code with the chosen PostgreSQL architecture and mitigate issues related to inter-database dependencies:
[DDL] CONVERT_DATABASE_TO_SCHEMA https://support.ispirer.com/guides/migration-toolkit/command-line/sqlways-ini/ddl-section#:~:text=CONVERT_DATABASE_TO_SCHEMA
[DDL] CONVERT_DBLINK_TO_SCHEMA
https://support.ispirer.com/guides/migration-toolkit/command-line/sqlways-ini/ddl-section#:~:text=CONVERT_DBLINK_TO_SCHEMA
Schema mapping options:
https://support.ispirer.com/knowledge-base/database-migration/tips-and-tricks/schema-mapping
In any case, the process involves creating a project directory and an ODBC connection for every migrated database: https://confluence.ispirer.org/spaces/DM/pages/189793336/Project+Directory
Let us assume that we have two databases: db1_db and db2_db. There is a procedure in the db2_db database that references db1_db. To convert them, you need to use two different projects with separate project directories.
Each project must use its own ODBC connection pointing to the corresponding source database.
Both projects share the same target database settings, so the import is performed into the same target database.
For both project directories, set the following options in the [DDL] section:
- EMPTY_SCHEMA = No
- OUTSCHEMA = <source database name>
As a result, objects from DB #1 will be placed into the db1_db schema, and objects from DB #2 into the db2_db schema.
Additionally, configure the following options in the [DDL] section:
- CONVERT_DATABASE_TO_SCHEMA=Yes
- CONVERT_DBLINK_TO_SCHEMA=Yes
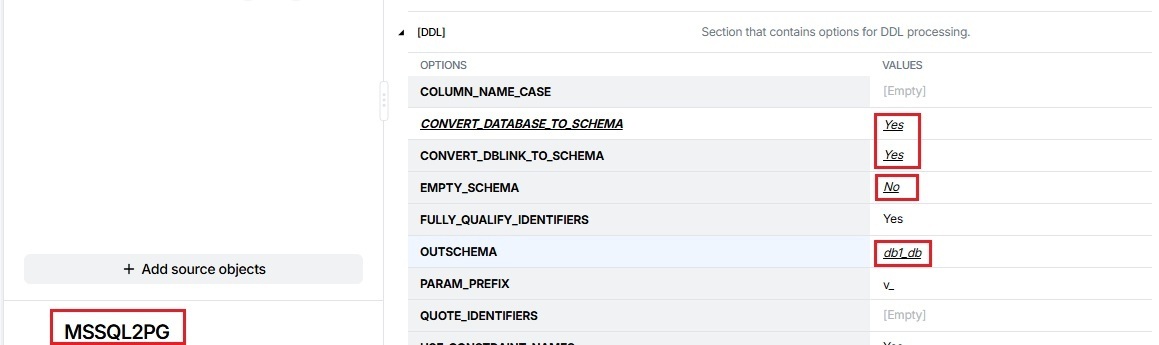
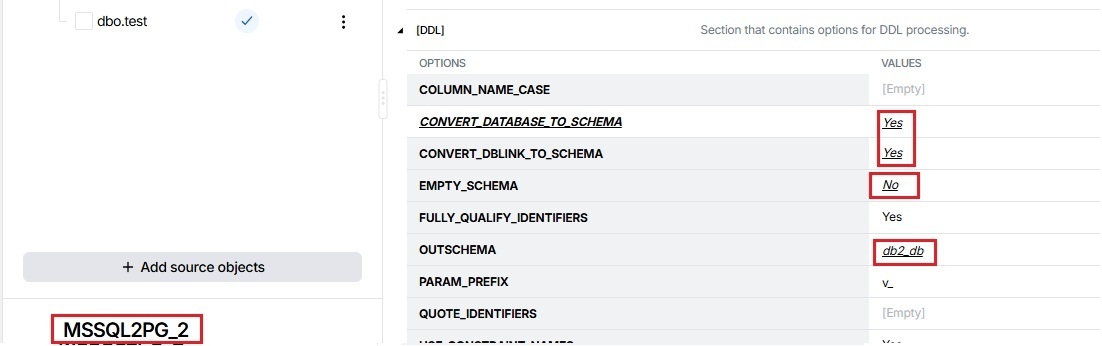
The conversion result is as follows.
| DB #1 | DB #2 |
|---|---|
create or replace procedure db1_db.proc1(INOUT SWV_RefCur refcursor default null, INOUT SWV_RefCur2 refcursor default null) LANGUAGE plpgsql AS $$ DECLARE v_t VARCHAR(100); BEGIN open SWV_RefCur for select CONCAT(COALESCE(p,''),COALESCE(v_t,'')) from db1_db.tab1 where 1 = 1; open SWV_RefCur2 for select CONCAT(COALESCE(v_t,''),COALESCE(p,'')) from db1_db.tab1 where 1 = 1; END; $$; | create or replace FUNCTION db2_db.proc2()
RETURNS TABLE
(
col VARCHAR
) LANGUAGE plpgsql
AS $$
DECLARE
v_t VARCHAR(100);
BEGIN
CALL db1_db.proc1();
return query
select CONCAT(COALESCE(p,''),COALESCE(v_t,'')) from db1_db.tab1
where id = cast('1' as INTEGER);
END; $$;
|
As shown above:
- Procedure proc2 is assumed to have only one result set and has been converted to a RETURNS TABLE function.
- References point to the correct schemas.
- The id column’s datatype was correctly identified as INTEGER, and a cast was added in the WHERE clause to handle the type difference.
However, the procedure call to db1_db.proc1 in DB #2 does not include the INOUT REFCURSOR parameters.
This occurs because it is not possible to determine from the first database whether these REFCURSORs are required.
To detect and convert this correctly, the full procedure definition from DB #1 would need to be accessible from DB #2, which is not the case in our tool.
This type of issue requires manual correction.
Here is the manually adjusted version of proc2:
create or replace procedure db2_db.proc2(
INOUT SWV_RefCur refcursor default null,
INOUT SWV_RefCur2 refcursor default null,
INOUT SWV_RefCur3 refcursor default null
) LANGUAGE plpgsql
AS $$
DECLARE
v_t VARCHAR(100);
BEGIN
CALL db1_db.proc1(SWV_RefCur, SWV_RefCur2);
open SWV_RefCur3 for
select CONCAT(COALESCE(p,''),COALESCE(v_t,'')) from db1_db.tab1
where id = cast('1' as INTEGER);
END; $$;
|
Related Topics
If you have any questions or face any difficulties, please contact our support team at support@ispirer.com